CLIアプリケーションのためのTyper
Typerとは
TyperはCLIアプリケーションを作成するためのライブラリです.
Typerの特徴は大きく以下になります.
- 直感的なコーディング
- 使いやすさ
- 少ない量のコーディング
- 導入の簡単さ
- 拡張性
省コストと拡張性を備えたライブラリで,シンプルで使いやすいが故に複雑なカスタマイズができないのかと思いきや,必要に応じてオプション引数やサブコマンドなどの複雑さを備えたCLIアプリケーションを作成したい場合にも対応できるようになっています.
現在の最新バージョンは 0.3.2 となっており,Pythonは3.6以上が対応している様です.より詳細な情報は公式ドキュメントを参照してみてください.
インストール
実行環境は以下となっています.
$ sw_vers ProductName: Mac OS X ProductVersion: 10.14.6 BuildVersion: 18G6042 $ python -V Python 3.9.1
ライブラリのインストールはpipで簡単に行えます.
$ pip install typer
使い方・実装方法
早速Typerの実装方法を説明していきたいと思います.
CLI Arguments
最初はAugmentsによる引数の利用法です.
Typerでは以下の様に実装していきます.
typer.runメソッドで引数に実行したい関数を指定してあげるだけです.その際に,実行する関数(main)で定義した引数(name)がコマンドラインで実行する時の引数かつ必須パラメータとなります.ちなみにドキュメントではType Hintsにて引数の型を指定していますが,この記載方法でなくても動作します.
#!/usr/bin/env python # -*- coding: utf-8 -*- import typer def main(name: str): print(f"Hello {name}") if __name__ == "__main__": typer.run(main)
早速実行してみましょう.
main.py を実行する際に与えた引数が内部で利用できていることが見てとれます.また,上記の実装方法でTyperを利用した場合は引数指定が必須となるため,引数を指定しないで実行した場合はエラーとなります.
# 引数を指定して実行 $ python main.py Japan Hello Japan # 引数を指定せずに実行 $ python main.py Usage: main.py [OPTIONS] NAME Try 'main.py --help' for help. Error: Missing argument 'NAME'.
引数にデフォルト値を設定する場合は以下の様にします.
Argument クラスを用いてインスタンス化する際にデフォルト値を指定した変数を引数に与えることで実現できます.
#!/usr/bin/env python # -*- coding: utf-8 -*- import typer def main(name: str = typer.Argument("World", help="出力する文字列")): print(f"Hello {name}") if __name__ == "__main__": typer.run(main)
先ほどは引数を与えない場合はエラーとなっていましたが,Argument にてデフォルト値を指定した場合はエラーにはならずデフォルトで指定した文字列が利用されています.上記例ではデフォルト値として World が設定されているので Hello World と出力されていることが見て取れますね.
# 引数を指定して実行 $ python main.py Japan Hello Japan # 引数を指定して実行 $ python main.py Hello World
Augumentには --help オプションにてコマンドの利用方法を表示するhelpテキストを記載することも可能です.--help オプションを表示してみると引数のhelpテキストが表示されていることが確認できます.
$ python main.py --help Usage: main.py [OPTIONS] [NAME] Arguments: [NAME] 出力する文字列 [default: World] Options: --install-completion [bash|zsh|fish|powershell|pwsh] Install completion for the specified shell. --show-completion [bash|zsh|fish|powershell|pwsh] Show completion for the specified shell, to copy it or customize the installation. --help Show this message and exit.
CLI Options
続いてオプションを利用する方法について記載します.
オプションと引数の違いですがコマンドのオプションは「プログラムの動作を指定するもの」で引数は「動作の対象を指定するもの」と把握しておきましょう.
実装は先ほどの引数の場合には Augment クラスを利用してましたが,オプションの場合には Option クラスを利用するだけです.Augument と同様にデフォルトのパラメータを指定すること,helpテキストを定義することが可能です.
#!/usr/bin/env python # -*- coding: utf-8 -*- import typer def main( name: str = typer.Argument("World", help="出力する文字列"), status: str = typer.Option("Great", help="状態を表す文字列"), age: int = typer.Option(None, help="年齢を表す数字") ): if age: print(f"Hello {name}! I am {age}") else: print(f"Hello {name}! I am {status}") if __name__ == "__main__": typer.run(main)
上記のコードを実行した結果を確認してみます.
オプションを指定せずに実行した場合はデフォルトのパラメータが利用されるので,条件文の if age が else の処理シーケンスに入るので Hello World! I am Great が出力されます.オプションを指定した場合は age に 20 が指定され, if age が True となるためHello World! I am 20 が出力されています.
# 引数の指定なし $ python main.py Hello World! I am Great # 引数指定なしでオプションあり python main.py --age 20 Hello World! I am 20
併せて オプション のhelpテキストも確認してみましょう.
オプションに status と age がちゃんと追加されているのが見れました.
$ python main.py --help Usage: main.py [OPTIONS] [NAME] Arguments: [NAME] 出力する文字列 [default: World] Options: --status TEXT 状態を表す文字列 [default: Great] --age INTEGER 年齢を表す数字 --install-completion [bash|zsh|fish|powershell|pwsh] Install completion for the specified shell. --show-completion [bash|zsh|fish|powershell|pwsh] Show completion for the specified shell, to copy it or customize the installation. --help Show this message and exit.
また,オプションでは Option クラスの引数にpromtパラメータを指定してあげると,エラーを表示する代わりに不足しているパラメータをコマンドライン上で対話形式で入力することができます.
#!/usr/bin/env python # -*- coding: utf-8 -*- import typer def main( name: str = typer.Argument("World", help="出力する文字列"), status: str = typer.Option("Great", help="状態を表す文字列"), age: int = typer.Option(None, help="年齢を表す数字", prompt="Please tell me your age") ): if age: print(f"Hello {name}! I am {age}") else: print(f"Hello {name}! I am {status}") if __name__ == "__main__": typer.run(main)
自身が作成したCLIアプリケーションを別の人が利用する際に,アプリケーション側で対話形式での入力機能を持っていると入力するべきパラメータが分かりやすいので非常に有効なツールになると思います.
$ python main.py Please tell me your age: 12 Hello World! I am 12
SubCommand
サブコマンドの利用もTyperで実装可能です.
これまでの引数やオプションと違って Typer クラスを用いて,生成したインスタンスを使ってサブコマンドに利用したい命名と同じ名前で定義したメソッドに対してデコレータを付与することでサブコマンドが利用できます.
以下では preprocess と train ,postprocess のサブコマンドを定義しています.
#!/usr/bin/env python # -*- coding: utf-8 -*- import typer app = typer.Typer() @app.command() def preprocess(subcommand: str = typer.Argument('preprocess')): print(f"select command '{subcommand}'") @app.command() def train(subcommand: str = typer.Argument('train')): print(f"select command '{subcommand}'") @app.command() def postprocess(subcommand: str = typer.Argument('postprocess')): print(f"select command '{subcommand}'") if __name__ == "__main__": app()
3つのサブコマンドが定義できて利用できていることを実行して確認します.
サブコマンドとして train を指定したら select command 'train'が表示されております.サブコマンドと引数の組み合わせも簡単に実装できてますね.
$ python main.py train select command 'train' $ python main.py train test select command 'test'
まとめ
今回は『CLIアプリケーションのためのTyper』というタイトルで引数やコマンドラインオプションなどを簡易に実装できるツールとしてTyperを実装例とあわせて紹介しました.
機械学習でアドホックに分析する際にはJupyter Notebookを利用するため,あまりCLIアプリケーションと関わりがない人もおられると思います.一方で,分析した後のシステムへのインプリの段階では多分に漏れなくCLIなどのPythonコードを記述することになると思います.その際にTyperを用いることでコマンドラインで学習や推論と行った処理を分けるプログラムを簡単に実装できるのはありがたいですね.今後も積極的に活用して行きたいと思います.
参考資料

データ分析におけるキャリブレーション
キャリブレーションとは
Calibration(以下,キャリブレーション) とは予測モデルの誤差分布を改善するための後処理の技術になります.
機械学習のモデルを構築してシステムにインプリする前に,モデルから得られるスコア値と実測値の誤差における分布や推定がどの程度適切に行われるかを知ることは非常に重要です.そこで今回は一般的なキャリブレーション手法について記していきます.
クラス分類におけるキャリブレーション
まずはじめにクラス分類問題における評価指標とモデル出力について説明します.
クラス分類における機械学習モデルの評価指標としてはaccuracyやF値,マクロ平均などがあり,その他にもloglossやMSE,ROCAUCと言った指標が使われます.そして,これらの指標は一般的にモデルから得られる出力値である0〜1の連続値より得られます.ここで問題となってくるのがこのモデルから得られる出力値を確率とみて判断することが適切で,信頼できる確率の値となっているかということです.
ここで実世界で扱うデータを考えたときに,分類問題で扱うデータは高いインバランス性を備えたデータであることが往々にしてあります(以下で記載の図のように各クラスで偏りがある状態を指します).そのため,我々はモデルを構築する際にアンダーサンプリングしてモデリングを実施しますが,これによってモデルにバイアスを生じさせる結果に繋がります.つまり,ここで生成されたモデルは実際の発生確率と異なるデータ分布によって学習されたモデルとなるため,予測されたスコア値が実際の発生確率の分布を近似できていない可能性が高いということです.
このように明らかにモデルの出力が実際の確率分布を捉えられていない場合もある中で,出力値を確率として扱いたい場合にはキャリブレーションによる補正が必要になってきます.ここまででキャリブレーションの必要性が理解できたところで次からは利用方法について解説していこうと思います.

キャリブレーションの評価指標
ここからはキャリブレーションの利用方法について記載していきます.
早速キャリブレーションの説明といきたいところですが,キャリブレーションを実施する前にモデルから得られたスコア値が本当にキャリブレーションが必要かどうかといった信頼性を確認する必要があります.
モデルのスコア値が信頼できる確率値となっているのかを測定する方法としては主に以下のようなものがあります.
- Reliability Diagram
- Expected Clivation Error(ECE)
- Maximum Calibration Error(MCE)
それぞれについて簡単に説明しておきます.
Reliability Diagram
Reliability Diagramとは予測モデルによって得られたスコア値に対してプロットされた事象の観測頻度のグラフとなります.キャリブレーションの可視化では頻繁にこのグラフが用いられます.
横軸にはビン毎の予測されたスコア値の平均を,縦軸には各ビン毎のポジティブなラベルの割合を示したものになります.要するに,y=x 上にプロットが近くにつれて予測値を確率として扱う信頼度が高いということが言えます.
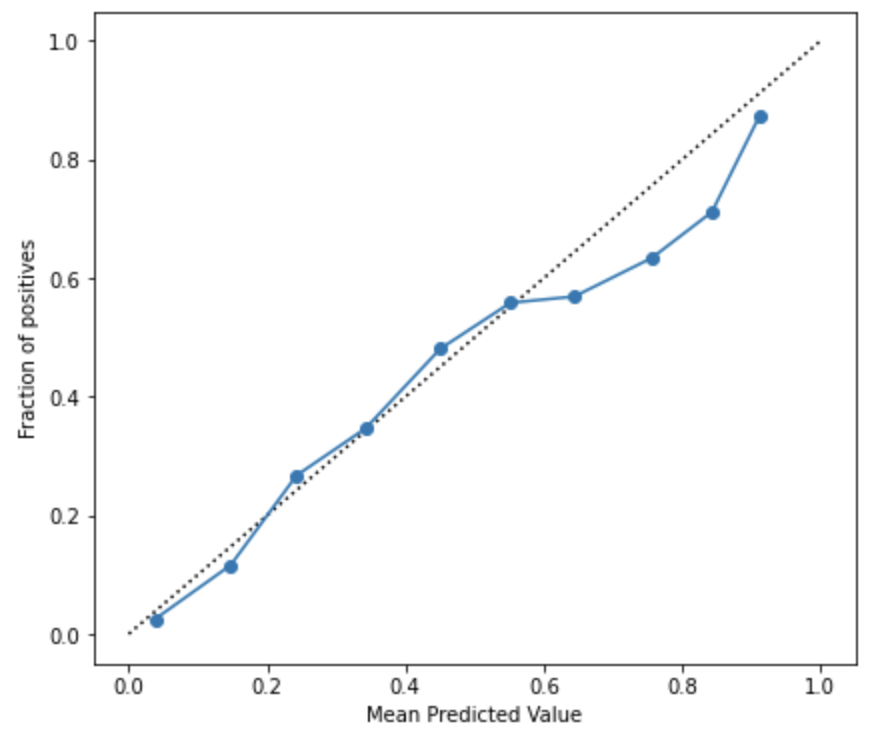
Expected Calibration Error(ECE)
ECEはビン毎の正解ラベルの割合と予測確率の誤差に対して各ビン毎のデータ数をもとに加重平均した指標です.当然のことながらECEの値が小さい方が信頼性の高い確率予測であることを示しています.ECEは広くキャリブレーションの誤差を計測する方法として利用されていますが,最近ではECEよりも適切なキャリブレーション評価指標としていくつかの別手法を提案した論文*1も散見されていますので,問題に応じて適切な評価指標を選択していく必要があります.
Maximum Calibration Error(MCE)
MCEは各ビンの誤差の中で最も大きい誤差を評価する指標です.もっとも悪いシナリオの影響を最小限に抑えようとするときに役立ちます.ECEと同様に値が小さい方がより信頼性の高い確率予測であることを示します.
キャリブレーション方法
さて,本命でありますキャリブレーション方法についてです.
メジャーな手法としては以下があります.
- Isotonic Regression
- Plat Scaling
以下ではそれぞれについて簡単に説明していきます.
Isotonic Regression
Isotonic Regressionは2値分類に限定して利用できる手法でノンパラメトリックな手法です.非減少関数をデータに適合させます.
ノンパラメトリックな手法のため,様々な形状の Reliability Diagram において適応することができます.しかし,その反面でOverfitを避けるためにより多くのデータが必要となるといった制約が存在します.また,データ量が少ない場合には後述する Platt Scaling よりも結果が悪くなることが指摘されているため,利用の際には注意が必要です.
Platt Scaling
Platt Scalingは説明変数をモデル出力値f(x)、目的変数を正解ラベルとしてSigmoid関数にフィットさせ、そのSigmoid関数に通した値をCalibrationした値とする方法です.
一般的に,この方法はキャリブレーションされていないモデルの信頼性が低く、高出力と低出力の両方で同様のキャリブレーション誤差がある場合に最も効果を発揮します.故に境界部分を厳しく判別するSVMなどでは高い効果が得られるようです.
また,Isotonic Regression との住み分けですが,Platt Scaling は、Reliability Diagram がSigmoid形状である場合にのみ大きく作用することから、Sigmoid形状以外の場合ははIsotonic Regressionを使用するのが良さそうです.
ここでは頻繁に出てくるキャリブレーション手法を取り上げましたが,記載した2つの手法以外にもニューラルネットワークに特化してキャリブレーションする手法*2などもありますのでさらに別の手法を知りたい方はそちらも参考にしてみてください.
では,ここまででキャリブレーションにおける指標と手法について述べてきたので具体的な実装方法について以下では記載していきます.
キャリブレーション実践
公開データセットを用いて予測モデルの構築と推論を行って取得したスコア値に対して Reliability Diagram の確認とキャリブレーション実施後の Reliability Diagram の変化を確認していきます.
動作環境
実行環境は以下となっています.
$ sw_vers ProductName: Mac OS X ProductVersion: 10.14.6 BuildVersion: 18G6042 $ python -V Python 3.9.1
利用データ
今回利用するデータはこちらのKaggleで公開されている「Telco Customer Churn」のデータセットです.
このデータセットは説明変数として顧客毎のインターネット利用やサポートなどのサービス利用有無のデータが含まれており,目的変数はChurnと呼ばれるカラムで顧客が先月中に退会したかどうかを示すフラグとなっています. 以下ではこのデータを用いて顧客が退会するかどうかの2値分類のタスクを考えてモデルを構築していきます.加えて,その過程でキャリブレーションについても同様に実施していきます.
実装例
まずは通常のモデリングと同様に予想モデルを構築して行きます.
import os import sys import numpy as np import pandas as pd import seaborn as sns import category_encoders as ce import matplotlib.pyplot as plt from IPython.display import display import lightgbm as lgb from sklearn.metrics import auc, roc_auc_score from sklearn.model_selection import train_test_split from sklearn.calibration import calibration_curve # データの読み込み df = pd.read_csv("data/telecom/WA_Fn-UseC_-Telco-Customer-Churn.csv") df.head() # 前処理 df = df[df.TotalCharges != " "] df.TotalCharges = df.TotalCharges.astype(float) df.replace({'Churn': {"Yes": 1, 'No': 0}}, inplace=True) df.dropna(how='any', axis=0, inplace=True) # カテゴリ変数のエンコード encode_cols = [ 'gender', 'Partner', 'Dependents','PhoneService', 'MultipleLines', 'InternetService', 'OnlineSecurity', 'OnlineBackup', 'DeviceProtection', 'TechSupport', 'StreamingTV', 'StreamingMovies', 'Contract', 'PaperlessBilling', 'PaymentMethod', ] ce_oe = ce.OneHotEncoder(cols=ordinal_encodes, handle_unknown='impute') df = ce_oe.fit_transform(df) # 学習モデル生成 target = 'Churn' iD = 'customerID' SEED = 40 test_size = 0.15 val_size = 0.05 predictors = [col for col in df.columns if col not in [target, iD]] X_train, X_test, y_train, y_test = train_test_split(df[predictors], df[target], test_size=test_size, random_state=SEED) X_train, X_val, y_train, y_val = train_test_split(X_train, y_train, test_size=val_size, random_state=SEED) lgb_m = lgb.LGBMClassifier( boosting_type='gbdt', objective='binary', learning_rate=0.005, max_depth=-1, num_boost_round=1000, lambda_l1=1, lambda_l2=0, min_child_weight=.5, subsample=.8, ) lgb_m.fit(X_train, y_train) # テストデータからのスコア計算 y_pred = lgb_m.predict_proba(X_test)[:, 1]
モデルが生成できたので精度を確認してみます.
AUCを評価指標としてROC Curveを出力します.また,ここでReliability Diagramも合わせて可視化します.
def viz_roc_curve(y_test, y_pred): """ Args: y_test: (np.array) テストラベルのリスト y_pred: (np.array) 予測ラベルのリスト """ fpr, tpr, thresholds = roc_curve(y_test, y_pred) _auc = auc(fpr, tpr) fig, ax = plt.subplots(figsize=(10,6)) plt.plot(fpr, tpr, color='darkorange',label='ROC curve (area = %0.2f)' % _auc) plt.plot([0, 1], [0, 1], color='navy', linestyle='--') plt.xlabel('False Positive Rate') plt.ylabel('True Positive Rate') plt.xlim([0.0, 1.0]) plt.ylim([0.0, 1.05]) plt.legend(loc="lower right") plt.show() def viz_calibration_curve(y_test, y_pred, name): """ Args: y_test: (np.array) テストラベルのリスト y_pred: (np.array) 予測ラベルのリスト name: (str) グラフタイトルに表示する文字列 """ frac_of_pos, mean_pred_value = calibration_curve(y_test, y_pred, n_bins=10) fig, ax = plt.subplots(1, 2, figsize=(15,6)) ax[0].plot([0, 1], [0, 1], "k:", label="Perfectly calibrated") ax[0].plot(mean_pred_value, frac_of_pos, marker="o", label=f'{name}') ax[0].set_ylabel("Fraction of positives") ax[0].set_ylim([-0.05, 1.05]) ax[0].legend(loc="lower right") ax[0].set_title(f'Calibration plot ({name})') sns.distplot(y_pred, bins=100, label='predicted score', ax=ax[1]) ax[1].legend(loc='upper right') ax[1].set_xlim([-0.05, 1.05]) plt.show() # AUCとReliability Diagramの可視化 viz_roc_curve(y_test, y_pred_test) viz_calibration_curve(y_test, y_pred, 'lightgbm')
AUCは85%となっており,まずまずの精度が出ていることを確認しました.

Reliability Diagramはスコア値が高くなるに連れて誤差が大きくなっていますが,スコア値を確率として扱うことに関して概ね乖離はなさそうに見えます.
いろいろ調べていくとLightGBMの2値分類ではloglossを最適化することからキャリブレーションは必要ないと言う内容の記事も散見されました.loglossでは誤差の幅も考慮されることから実測と予測が乖離しているほどペナルティーが加算されるため,学習が進むにつれて予測が高い確度で当てられるものはスコア値が高くなるため実際の確率に近しくなっていくことは感覚と近しい部分があります.ですが,必ずしもキャリブレーションを実施しなくても良いとは言い切れないので,必要に応じてReliability Diagramを可視化して確認する方が良いでしょう.

続いて学習時のアルゴリズムをSVMにして精度とReliability Diagramを確認していきましょう.
from sklearn.svm import SVC # SVMでのモデル学習 svc = SVC(max_iter=10000, probability=True) preds_svc = svc.fit(X_train, y_train).predict(X_test) # テストデータからのスコア計算 probs_svc = svc.decision_function(X_test) pred_svc = (probs_svc - probs_svc.min()) / (probs_svc.max() - probs_svc.min()) # AUCとReliability Diagramの可視化 viz_roc_curve(y_test, pred_svc) viz_calibration_curve(y_test, pred_svc, 'SVM')
SVMではAUCが79%となりました.
LightGBMと比べると精度が落ちていますが,そこそこの精度が出ていますね.

続いてReliability Diagramですが,先ほどのLightGBMと比べてReliability Diagramがかなりスコア値が確率と乖離があるようになりました.全体的にスコア値が実際の確率よりも少し高めになっている様子が見受けられます.
では,このSVMのモデルをisotonic regressionとPlatt Scalingの2つの手法でキャリブレーションしてみます.

from sklearn.calibration import CalibratedClassifierCV # Isotonic Regressionでのキャリブレーション isotonic = CalibratedClassifierCV(svc, cv=5, method='isotonic') isotonic.fit(X_train, y_train) pred_svc_isotonic = isotonic.predict_proba(X_test)[:,1] # Platt Scalingでのキャリブレーション platts_scaling = CalibratedClassifierCV(svc, cv=5, method='sigmoid') platts_scaling.fit(X_train, y_train) pred_svc_platt = platts_scaling.predict_proba(X_test)[:,1] # AUCとReliability Diagramの可視化 viz_calibration_curve(y_test, pred_svc_isotonic, 'SVM [isotonic]') viz_calibration_curve(y_test, pred_svc_platt, 'SVM [platt scaling]')
キャリブレーションの実装自体はscikit-learnのCalibratedClassifierCV クラスにて実装されているので利用自体はとても簡単です.Isotonic Regressionと Platt Scaling の使い分けはパラメータで指定するだけですので分かりやすいですね.
Isotonic Regressionではキャリブレーション前のReliability Diagramよりも低いスコア値の場合が適切に補正されているのが見てとれます.
一方で高いスコア値の場合はキャリブレーション前よりは改善していますが,低いスコア値の時に比べると若干の誤差が生じているようです.

Platt Scalingでも同様に低いスコア値の時は確率として扱っても問題なさそうですが,一方で高いスコア値の時は確率が高めに見積もられてしまっているようです.とは言え,キャリブレーションを適応することでスコア値を確率として扱うための補正が行えることが分かりました.

まとめ
今回はKaggleのデータセットを題材として,スコア値を確率として扱う信頼性の確認方法からスコア値を確率として扱うためのキャリブレーションについて説明しました.
最近ではニューラルネットワークでキャリブレーションを扱う手法やECEやMEC以外の新しい評価指標も提案されていたりするのでこちらも継続して情報をアップデートする必要がありそうです.データ分析では前処理やモデル構築の部分がフィーチャーされがちですが,こういった後処理部分でもまだまだ学ぶべき項目がたくさんありますね.機械学習つよつよエンジニアへの道のりは長いですが継続して今後も精進していきましょう.
参考資料
matplotlibの文字化け解決の最適解『japanize-matplotlib』
matplotlibの文字化け
データ分析を行なっている方であれば当然EDA(探索的データ分析)のフェーズで自身が扱っているデータを理解することに努めると思います.このプロセスを丁寧に行うことで「扱っているデータがどのような情報を持ってるのか」,「データ分布がどのような形状になっているか」,「欠損値がどれくらい含まれているのか」などを把握することができます.
そして,分析者は理解したデータ内容を第3者にレポーティングするという責任を負っており,分かりやすく伝えるために データ可視化 を自在に使いこなすことがが非常に重要となってきます.
その可視化の際に頻繁に出くわす問題が Matplotlib を用いた可視化における文字化けです.データにマルチバイト文字を含まずとも,聴衆に合わせて仕方なく日本語でラベルを付与してグラフを可視化することによって文字化けが生じるなんてことも往々にしてあります.個人的には英語表記で可視化すれば済む話だと思うのですが,伝わりやすさという観点では日本語を利用した方が良い場合もあります. そこで,今回はこの Matplotlib を用いた可視化におけるマルチバイト文字に対する対処法について記載します.
ちなみに余談にはなりますが,データ可視化では以下のサイトが便利でよく参考にさせてもらっています.可視化パターンとPythonでの実装方法がセットになっているため効率的な可視化ライフを送ることができます.是非活用してみてください.
また,以下の記事ではケース別でどの可視化を選択するべきかをわかりやすくまとめてくれています.こちらも非常に役立つので適宜活用していくことをお勧めします.
対処法
少し話がそれましたが,ここからは本題の Matpliotlib におけるマルチバイト文字の文字化けへの対処法についてです.
具体的には以下の対処法があります.
個人的にマルチバイト文字をコストをかけずに文字化けすることなく可視化する方法としては 3番目のjapanize-matplotlibが有効 だと思います.そのため,以降ではjapanize-matplotlibの使い方について説明していきます.
1番目と2番目の対応を知りたいという方は以下のサイトが詳しく記載していますのでそちらを参照してみてください.
japanize-matplotlib
japanize-matplotlibとは Matplotlib を日本語表示に対応させるためのPythonライブラリです.
importと同時に IPAexGothic のフォントを自動で追加して,追加したフォントを利用する設定処理を適応することで日本語が文字化けしないようにしています.
また,Matplotlibのバージョンが 3.2 以上の場合は createFontList メソッドが非推奨になったため,createFontListを利用すると警告が表示されるようになりました.そのため,japanize-matplotlibでも内部で createFontList を利用していることから警告が表示されるようになっていましたが,こちらは2020年5月にソースコードが以下のように修正されて警告が出力されないように対応されています.
is_support_createFontList = LooseVersion(matplotlib.__version__) < '3.2' if is_support_createFontList: font_list = font_manager.createFontList(font_files) font_manager.fontManager.ttflist.extend(font_list) else: for fpath in font_files: font_manager.fontManager.addfont(fpath) matplotlib.rc('font', family=FONT_NAME)
次からはインストールと利用方法について記載していきます.
実行環境は以下となっています.
$ sw_vers ProductName: Mac OS X ProductVersion: 10.14.6 BuildVersion: 18G6042 $ python -V Python 3.6.9
インストールはpipにて実施できます.
$ pip install japanize-matplotlib
続いてjapanize-matplotlibの利用方法です.
まず,通常の Matplotlib でマルチバイト文字を出力した場合のグラフを確認してみましょう.scikit-learnに含まれるワイン成分に関するデータについて,アルコール度数とりんご酸の関係を散布図で出力してみます.
import numpy as np import pandas as pd import matplotlib.pyplot as plt from sklearn.datasets import load_wine data = load_wine() df = pd.DataFrame(data.data, columns=data.feature_names) # Visualization fig, ax = plt.subplots(figsize=(12, 8)) plt.scatter(df.alcohol, df.malic_acid, cmap="Blues", alpha=0.8, edgecolors="grey", linewidth=2) plt.xlabel("アルコール") plt.ylabel("リンゴ酸") plt.title("2属性間の散布図") plt.show()
上記ソースコードを実行すると以下のようなグラフが可視化されるはずです.しっかり文字化けしていますね.
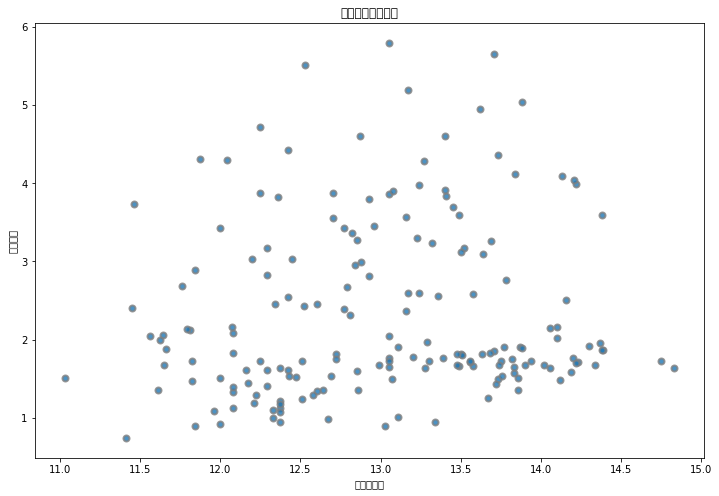
次にjapanize-matplotlibを利用して同じ要領で可視化を行ってみます. 利用方法は Matplotlib をインポートした後に japanize_matplotlib をインポートするだけです.
import numpy as np import pandas as pd import matplotlib.pyplot as plt import japanize_matplotlib from sklearn.datasets import load_wine data = load_wine() df = pd.DataFrame(data.data, columns=data.feature_names) # visualization fig, ax = plt.subplots(figsize=(12, 8)) plt.scatter(df.alcohol, df.malic_acid, cmap="Blues", alpha=0.8, edgecolors="grey", linewidth=2) plt.xlabel("アルコール") plt.ylabel("リンゴ酸") plt.title("2属性間の散布図") plt.show()
文字化けしていたマルチバイト文字がちゃんと表示されていますね.
このように簡単に文字化けを修正することができるので是非活用してみることをお勧めします.

まとめ
今回は Matpliotlib におけるマルチバイト文字利用おける対応を「japanize-matplotlib」を中心にまとめてみました.
以前は私もフォントの設定を変更して文字化け対応をしていたのですが,japanize-matplotlibに出会ってからはこちらを利用させてもらっています.毎回スクリプトで処理を記述するのも,設定ファイルを作成する手間も省けるので是非活用してみてください.

令和2年秋季応用情報技術者試験の受験結果は...
経緯
過去の記事で「応用情報技術者試験に合格するまで」というタイトルで内容を記載しています.
その中で令和2年秋季の応用情報技術者試験の受験報告と自己採点を記載したのですが,正式な受験結果を記載していなかったのでこちらで展開しようと思います.
受験結果
受験結果は無事「合格」でした.

自己採点では以下の通りでしたが,実際は自己採点より下方修正された点数でした.午後の点数は割とギリギリでしたね...
| 試験項目 | 自己採点 | 試験結果 |
|---|---|---|
| 午前試験 | 90点 | 88点 |
| 午後試験 | 74点 | 69点 |
午前試験は選択方式ということもあり解答速報による採点結果と公式の採点結果がほとんど同じであるため,早く結果を知りたいという方の自己採点は有効そうですね.一方の午後試験は記述式の部分があるので公式の試験結果を見てみないと分からない場合もありそうです.特に,自己採点が合格ラインである60点付近となった場合は試験結果が出るまで落ち着かない日々を過ごすことになると思います.
ただ何にせよ地道に勉強した結果は裏切らないので直前に詰め込む勉強法より地道にコツコツ勉強する方法で学習することを私は勧めます.勉強法については以前の記事に方法を記載しているのでそちらを是非参照してみてください.
次の試験に向けて
応用情報は情報処理技術者試験のレベル3の区分に位置付けられています.
次の試験としてレベル4の高度試験がありますので今後はそちらにも意識的に時間を作って挑戦していければと考えています.
レベル4の高度試験について少し紹介しておくと,高度試験では分野が分かれており,それぞれの分野でより深い知識と実務能力を要求されるようになります.私はマネジメントよりはテクノロジの領域を実際の仕事でも扱っているので,「ネットワークスペシャリスト試験」か「データベーススペシャリスト試験」のどちらかを受験しようと思います.というのも,高度試験の中でも難易度にムラがあり比較的取得しやすい資格となっているためです.
これから心機一転して勉強を始めることになりそうですが,高度試験の受験についても別の記事で勉強法やTips等をまとめていけたらと思います.
まとめ
試験勉強に真剣に取り組んでいたので素直に応用情報技術者試験に合格していて良かったです.今後も新しい知識を身に着けるためにより高度な資格取得を目指していこうと思います.
データ分析でもアルゴリズム『いもす法』
はじめに
データサイエンスを日常的に行う中で大量のデータを扱うことが往々にしてあります.その際に頻繁に発生してくる問題が膨大な計算量による待ち時間発生や計算が有限時間内に終了しないといった問題です.
私は特にこの待ち時間を非常に厄介だと感じていてます. 何故かと言うと,待ち時間が発生すると当該処理が終わるまで別の作業をして効率的に物事を実施しようと思うのですが,逆にこのタスクの切り替えによってオーバヘッドがかかってしまい非効率になってしまうためです.
例えば,英語長文読解の勉強をしている途中で急に洗濯の依頼をされ,洗濯が終わった後に勉強を再開しようすると,途中まで読んでいた内容を思い出すために長文を読み直したりすることがあると思います.このようにタスクの切り替えにはオーバーヘッドが付き物であり,労力がかかることがしばしばあります.
そのため,データ分析に関しても可能な限り待ち時間を少なくして集中して取り組むことが良いと考えています.こういった経験から実行速度やメモリ効率に影響してくるアルゴリズムを理解することは重要であると思っており,時間があるときに私はアルゴリズムの学習をしています.
そこで,今回はその学習過程で出会った『いもす法』というアルゴリズムについてまとめていこうと思います.
『いもす法』ってなんぞや
いもす法は「ある連続する区間に、ある数 v を足す」という操作をK回繰り返した結果を、計算量 O(N+K) で高速に計算する方法です.
これだけ聞くとどういう事を意味しているのか分かりづらいと思うので,処理の具体的なプロセスを以下に記載します.
- 加算処理
区間[a, b]にvを加算したいとき、a 番目の値にvを加算して b+1 番目の値に-vを加算する - 累積和
加算処理した結果を元に累積和を計算して結果を得る
要するに,いもす法では区間の入口で加算、区間の出口で減算をしたリストを作成して、リストの作成が終わったら前から順に累積和を計算していきます.この後ではPythonで実装した例を示していこうと思います.
また,いもす法の本家の解説は以下になります.より深い理解をしたい人は参照してください.
Pythonでの実装例
さて,いもす法をPythonを用いて実装してみようと思います. 実行環境は以下となっています.
$ sw_vers ProductName: Mac OS X ProductVersion: 10.14.6 BuildVersion: 18G6042 $ python -V Python 3.6.9
簡単のために長さがNの1次元配列を題材とします.
以下が今回扱う問題です.
長さが10のリストにおいて、 - 区間[1, 7]に2を加算 - 区間[4, 8]に3を加算 - 区間[0, 5]に5を加算 という3つの操作をしたときの最終結果はいくつか.
まず長さが10の配列を作成します.
N = 10 data = [0] * N
次に区間が [1, 7] に2を加算する処理を適応します.
この場合はリストのインデックスが 1 の時に 2 を加算して,インデックスが 8 の時に 2 を減算します.
a, b = 1, 7 v = 2 data[a] += v if b+1 != N: data[b+1] -= v
同様に区間 [4, 8] と [0, 5] に3と5をそれぞれ加算してリストを更新します.
a, b = 4, 8 v = 3 data[a] += v if b+1 != N: data[b+1] -= v a, b = 0, 5 v = 5 data[a] += v if b+1 != N: data[b+1] -= v
そして最後にこのリストより累積和を計算します.
ans = [0] * N for i in range(0, N): if i == 0: ans[i] = data[i] else: ans[i] = ans[i-1] + data[i] print(sum(ans)) #59
また,処理が冗長な部分を省いた場合のコードは以下となります.
# 要素のリスト作成 N = 10 data = [0] * N # 要素のリスト更新 rlist = [(1, 7, 2), (4, 8, 3), (0, 5, 5)] for a, b, c in rlist: data[a] += c if b+1 != N: data[b+1] -= c # 累積和の計算 ans = [0] * N for i in range(0, N): if i == 0: ans[i] = data[i] else: ans[i] = ans[i-1] + data[i] print(sum(ans))
実際の実装例を踏まえて『いもす法』の一連な流れが理解できたと思います.
今回の例ではリストの長さが小さいため,『いもす法』を使わずとも各区間について2重ループを回すことで結果を求めることができます.しかし,このリストの長さが非常に長くなった場合には計算が立ちゆかなくなってくるので『いもす法』はそう言った場合に非常に効力を発揮ので覚えておいて損はないと思います.
まとめ
今回はデータ分析の下支えとなるアルゴリズムに関して知識整理を兼ねてまとめてみました.
データ分析のゴールは分析して終わりではなく,データ分析で得られた知見を顧客までデリバリして価値を提供する事になります.そのデリバリの方法の1つとしてソフトウェアによる提供が多くあると思います.そういった観点からも開発サイドでアルゴリズムに精通することは決して無駄にはならないのでデータ分析と合わせて学習していくと良いと思います.
Pytorchにおけるモデル保存の使い分け
はじめに
TorchServeを利用してサービングを実施する際にモデルの保存方法についていくつかパターンがあり,TorchServeで保存したモデルを読み込む際にうまく動作しないといった事があったのでしっかり違いを把握しようと思ってこの記事を書いています.この記事を読んでくださっている人の中にもよく分からずに何となくPytorchにおけるモデル保存を実施している人もいるかと思いますのでそう言った方の参考になればと思います.ちなみにPytorchのバージョンは1.7.0を前提として話を進めます.
モデル保存パターン
まず保存パターンについて説明していきます.
公式では大きく2つのパターンでのモデル保存を解説しています.また,そのほかにもTorchScriptを利用したモデルの保存方法もあります.方法別で記載すると以下のパターンがモデル保存方法として実現する方法としてあります.
- state_dictを利用したモデルの保存/読み込み
- entire のモデル保存/読み込み
- TorchScriptによるモデル保存/読み込み
次から各パターンの特徴を実装例を交えて解説していきたいと思います.
各パターンの解説
ここからは先ほど列挙した各パターンのモデル保存方法を説明していきたいと思います.
前提情報としてモデル保存と読み込みを実装を交えて説明するためのモデルを以下に記載します.モデル自体はなんでも良いので適当に5層のMLPを定義しました.
import torch import torch.nn as nn import torch.nn.functional as F import torch.optim as optim from torch.utils.data import Dataset, DataLoader class MyModel(nn.Module): def __init__(self): super(MyModel, self).__init__() self.fc1 = nn.Linear(128, 64) self.fc2 = nn.Linear(64, 32) self.fc3 = nn.Linear(32, 16) self.fc4 = nn.Linear(16, 8) self.fc5 = nn.Linear(8, 2) def forward(self, x): x = F.relu(self.fc1(x)) x = F.dropout(x, p=0.5) x = F.relu(self.fc2(x)) x = F.relu(self.fc3(x)) x = F.relu(self.fc4(x)) x = self.fc5(x) return x model = MyModel()
state_dictのモデル保存
1番目の state_dict を用いたモデル保存について説明します.
state_dict はモデルで定義された各レイヤーにTensor形式のパラメーターをマッピングするための単純な辞書オブジェクトを返します.これによって,簡単にモデルを保存、更新、変更、復元できるようになります.
# モデル保存 torch.save(model.state_dict(), "models/model_state_dict.pth") # モデル読み込み model_state_dict = MyModel() model_state_dict.load_state_dict(torch.load("models/model_state_dict.pth"), strict=False)
model_state_dict.state_dict() を実行すると学習ずみのパラメータが正しく読み込まれているのが分かります.
また, state_dictを用いることによってGPUで学習したモデルをCPUで推論したり,CPUで学習したモデルをGPUで推論したりすることができます.そのため,Pytorchの公式ドキュメントでは state_dict が推奨されています.
# GPU to CPU # モデル保存 torch.save(model.state_dict(), "models/model_state_dict.pth") # モデル読み込み device = torch.device('cpu') model = MyModel() model.load_state_dict(torch.load("models/model_state_dict.pth", map_location=device)) # CPU to GPU # モデル保存 torch.save(model.state_dict(), "models/model_state_dict.pth") # モデル読み込み device = torch.device("cuda") model = MyModel() model.load_state_dict(torch.load("models/model_state_dict.pth", map_location="cuda:0")) model.to(device)
学習時と推論時で異なるプロセッサを利用する場合などはload関数を実行する際にmap_locationの引数にデバイスを指定してあげる必要があります.これによって,GPUで学習したモデルをCPUで読み込む際にはTensorを扱うストレージがCPUに動的再配置されるようになります.
逆に,CPUで学習したモデルをGPUde読み込む際も同様でload関数を実行する際にmap_locationの引数でTensorをマッピングするGPUデバイスを指定してあげる必要があります.ここで,GPUのどのデバイスに配置するのかを明示するためcuda:idの形式で指定してあげます.そして,CPUからGPUの場合では必ず model.to(torch.device('cuda')) を呼び出してモデルのパラメータであるTensorをCudaTensorに変換してあげてください.
entireのモデル保存
続いて,モデルとパラメータをセットで管理するモデル保存方法の説明です.
entire モデルではモデルに含まれるモジュール全体を保存することになります.メリットは少ないコード量で記述できることとその直感的な文法です.
# モデル保存 torch.save(model, "models/model_state_dict.pth") # モデル読み込み torch.load("models/model_state_dict.pth")
この方法では pickle モジュールを用いて保存されているおり,シリアル化されたデータが特定のクラスとディレクトリ構造にバインドされることになります.これによって,推論時のロードうやリファクタリングした場合に参照するパスが異なっていたりして致命的なエラーとなり利用できなくなります.このデメリットからも公式では非推奨となっています.
直感的で分かりやすいのですが,デメリットが大きすぎで実際に活用するシーンというのは少なそうです.
TorchScriptのモデル保存
まずTorchScriptについて簡単に説明します.
TorchScriptはPytorchで学習させたモデルをPython非依存な形でモデルを最適化してパラメータを保存することができます.この形式で保存したモデルはPython以外のC++やiOS,Androidといった様々な環境で読み込んで利用することが可能になります.
こちらの記事で分かりやすくまとめられてますので,TorchScriptについて詳しく知りたいという方は是非参照してみてください.
では,TorchScriptでモデルを保存する方法を以下に記載します.
# モデル保存 input_tensor = torch.rand(1, 128) model_trace = torch.jit.trace(model, input_tensor) model_trace.save('models/model_trace.pth') # モデル読み込み model_trace = torch.jit.trace('models/model_trace.pth')
TorchScript のモデルを作成するためにはサンプルデータを流して処理をトレースして変換を行うことで生成します.非常に簡単ですね.また,TorchScript のモデルを作成する方法にはトレースして生成する方法以外に直接的にモデルを記述する方法もあります.
べストな保存方法
さて,このパターンを踏まえてベストな保存方法について検討してみます.
まず,パターン2の entire のモデル保存ですがこちらは公式でも非推奨とされているので利用しない方が良いと思います.
次にパターン1の state_dictとパターン3の TorchScript のモデル保存ですが,こちらの2つは状況に合わせて使い分けを実施するのが良いです.
モデル作成途中やプロトタイプレベルで利用する場合にはパターン1のstate_dictによるモデル保存を利用します.TorchScriptでは最新の処理には対応していない場合があり,変換する際にエラー対応が必要になることがあります,そのため,試作レベルの時にはデバックに用する時間をかけるよりもスピード感を重要視して state_dict を利用する方が良いと思います.
そして,プロダクションフェーズの利用の際には TorchScript でのモデル保存を実施して最適化されたモデルを活用するといった使い分けが良いと言えます.TorchScriptも最近では改善や最適化が進んでいるので今後は全ての状況でTorchScriptでモデル保存する方が良いといった変化はあるかと思いますが,現状は上記のような使い方をするのがベストかと思います.
まとめ
今回はPytorchのモデル保存についてまとめてみました.
普段何気なく使っている人やTorchScriptを使ったことのない人にとって参考になればと思います.

TorchServe入門
TorchServeとは
TorchServeはPytorchで構築したモデルをサービングするためのモデルサービングライブラリです.
AWSとFacebookが連携して開発しているため,Pytorchのコミュニティと共に今後の発展が期待できます.また,GithubのスターもTensorflow Servingの4515と比べると見劣りしますが,2020年12月時点で1464と様々な人から注目されていることが分かります.
また,AWSとの親和性も高く,TorchServeによる推論サーバをSageMakerやEKS上に構築して,スケールアウトする事例を公式のブログにて公開しています.このようにプラットフォーム側がサポート・推奨しているライブラリを利用することは安心感がありますし,本番環境までを意識したモデル構築を実現できるTorchServeの存在は非常に大きいと思います.
私自身もこれまではPytorchで作成したモデルをデプロイする際には自身でAPIサーバの設計と実装,ログ設計,テストなど多くのことを検討・実施しておりましたが,TorchServeの登場によって多くのプロセスを簡略化することができるため非常に有効なツールだと感じています.
さて,以降ではTorchServeの紹介と独自で作成したオリジナルモデルをTorchServeにデプロイしてサービングを実践していきます.
アーキテクチャ
Pytorchのアーキテクチャは以下のようになっております.
TorchServeをデプロイするといくつかのコンポーネントが立ち上がります.Frontendと呼ばれるコンポーネントがInference APIを提供して推論用のAPIエンドポイントを提供します.モデルごとにエンドポイントが提供されるため,複数のモデルを同時に扱うことができます.
また,Process Orchestrationの部分ではManagement APIと呼ばれるモデルの登録やステータスを確認するためのエンドポイントも提供しています.モデル新規登録からバックエンドで動作するワーカーのスケールなどの制御を行うことができます.

- 構成要素
また,TorchServeで提供されるAPIはOpenAPIの標準仕様に則って作成されているため,APIインターフェース仕様を容易に理解できるようにもなっております.API仕様を説明したJson形式ドキュメントを介して以下に示すようなSwaggerUIも確認できるのでそちらも理解を手助けしてくれます.ドキュメントが手厚いのは利用者側からすると組織やグループで導入する際のハードルを下げる重要な要素になってくるので非常にありがたいです.

メリット
次にTorchServeのメリットを記述します.
やはりTorchServeのメリットは以下になると思います.
機械学習モデルを活用した機能のサービスへの導入高速化
機械学習で作成したモデルをTorchServeによってAPI提供することができるため,サービス導入までのリードタイムを短縮することが可能となりますモデル構築部分へのリソース注力
実際のビジネス現場ではモデルを構築して終わりではなく,それを活用してオペーレーションを最適化したり,ユーザに価値を届けたりします.そのため,モデル以外にもソフトウェア開発等にリソースを割く必要があるのですが.TorchServeによってその一部が簡略化できるためモデル部分にリソースを集中することができるようになりますオペレーションにおけるモデル運用の効率化
複数のモデルを統一されたプラットフォームでサービングやモデル管理ができるため,運用時のオペレーションを効率化することが可能になりますアナリストによるソフトウェア開発への介入
データサイエンティストがソフトウェア開発の領域に介入することを容易にするため,データサイエンティストがよりシームレスな顧客へのデリバリを可能にすることができます
このように大きなメリットがあるので小さいデメリットがいくつかあったとしても導入を検討する価値はあると思います.モデルをサービングする必要がある場合の実現方法の1つとして覚えておいて損はないはずです.
事前準備
TorchServeによるサービングを実践する前にモデル作成に必要なデータとTorchServeのインストール方法について記載します.
利用データ
今回利用するデータはUCI machine learning repositoryで公開されているadultデータセットになります.
このデータセットはユーザ属性と当該ユーザの年収が50Kを超えるかどうかを示すラベルのデータ内容から構成されています.そのため,分類タスクのデータセットとして一般的に用いられてます.これを使って予測モデルを以降で構築していこうと思います.
adultデータセットに含まれる属性値とその説明について簡単に以下にまとめておきます.
| カラム名 | 説明 | 変数 | 補足 |
|---|---|---|---|
| age | 年齢 | 連続値 | - |
| workclass | 労働階級 | カテゴリ変数 | 8種類 |
| fnlwgt | 国勢調査の人口重み | 連続値 | - |
| education | 学歴 | カテゴリ変数 | 16種類 |
| education-num | 教育期間 | 連続値 | - |
| marital-status | 世帯 | カテゴリ変数 | 7種類 |
| occupation | 職業 | カテゴリ変数 | 14種類 |
| relationship | 続柄 | カテゴリ変数 | 6種類 |
| race | 人種 | カテゴリ変数 | 5種類 |
| sex | 性別 | カテゴリ変数 | 2種類 |
| capital-gain | キャピタルゲイン | 連続値 | - |
| capital-loss | キャピタルロス | 連続値 | - |
| hours-per-week | 週当たりの労働時間 | 連続値 | - |
| native-country | 母国 | カテゴリ変数 | 41種類 |
| target | 年収ラベル | '>50K' = 1, '<=50' = 0 | - |
インストール
実行環境は以下のようになっています.
$ sw_vers ProductName: Mac OS X ProductVersion: 10.14.6 BuildVersion: 18G6042 $ python -V Python 3.6.9
TorchServeのインストールは以下の pip コマンドでインストールします.
# pytorch インストール $ pip install torch torchvision # torchserve インストール $ pip install torchserve torch-model-archiver
以上で環境構築は終わりです.
次からはモデル学習してTorchServeによる推論サーバをデプロイしていきましょう.
TorchServe実践
ここからが本題のモデルのデプロイ部分になります.
前置きが長くなりましたが,早速実際にモデルをデプロイしていきましょう.
モデル作成
まずデプロイするためのモデルの作成です.
ユーザ属性から年収が500ドルより高い収入を得るか得ないかを2値分類する予測モデルを構築していきます.
- Pythonライブラリのインポート
import numpy as np import pandas as pd import matplotlib.pyplot as plt import seaborn as sns import torch import torch.nn as nn import torch.nn.functional as F import torch.optim as optim from torch.utils.data import Dataset, DataLoader from sklearn.preprocessing import StandardScaler from sklearn.metrics import auc, roc_curve from sklearn.model_selection import train_test_split from sklearn.metrics import confusion_matrix, classification_report
- リスト定義
# データフレームに設定するカラムのリスト cols = [ 'age', 'workclass', 'fnlwgt', 'education', 'education-num', 'marital-status', 'occupation', 'relationship', 'race', 'sex', 'capital-gain', 'capital-loss', 'hours-per-week', 'native-country', 'target' ] # 標準化を適応するカラムのリスト scholar_cols = [ 'age', 'fnlwgt', 'education-num', 'capital-gain', 'capital-loss', 'hours-per-week', ] # ダミー化を実施するカラムのリスト category_cols = [ 'workclass', 'education', 'marital-status', 'occupation', 'relationship', 'race', 'sex', 'native-country' ]
カラム名のリスト,標準化を実施するカラム名のリスト,ダミー化を実施するカラム名のリストを事前に定義しておきます.後ほど,前処理の工程で利用します.
- データの読み込み
# UCIのデータセットを読み込み df = pd.read_csv('../data/adult.data', names=cols, header=None) # 不完全なデータをNanに置換 df = df.applymap(lambda d: np.nan if d==" ?" else d) # Nanのレコードを除外 df = df.dropna()
UCIのデータセットを読み込んだ後にデータに含まれている不完全なレコードを除去します.UCIのadultデータセットには欠損データが含まれており.『 ?』のレコードをNanに変換した後に dropna でレコード毎除外しています.
この時点でデータ数が 30162 になっているはずです.
- 前処理の実施
# targetカラム数値に変換 _, y = np.unique(np.array(df.target), return_inverse=True) df.loc[:, 'target'] = y # 連続値を標準化 sc = StandardScaler() features = sc.fit_transform(df.loc[:, scholar_cols].values) features df.loc[:, scholar_cols] = features # カテゴリ値をダミー化 df = pd.get_dummies(df, columns=category_cols)
処理としては大きく3つの前処理を実施しています.
1つは target 列を学習で扱えるように0と1のラベルに変換します.
そして残りの2つは連続値の標準化とカテゴリ変数のダミー化です.
- パラメータ定義とデータ分割
# 各種定数 SEED = 42 # シード値 BATCH_SIZE = 32 # バッチサイズ epochs = 20 # エポック数 learning_rate = 1e-3 # 学習率 device = 'cuda' if torch.cuda.is_available() else 'cpu' target = 'target' predictors = [col for col in df.columns if col not in target] input_num = len(predictors) # データを学習用とテスト用に分割 X_train, X_test, y_train, y_test = train_test_split(df[predictors], df[target], test_size=0.2, random_state=SEED)
学習で利用するパラメータを定義します.
バッチサイズは32でエポック数は20としています.また,全データのうちの2割をテストデータとして分割します.
- DatasetクラスとModuleクラスの定義
# 独自データセットの定義 class MyDataset(Dataset): def __init__(self, df, target): self.dataset = torch.Tensor(df.values) self.target = torch.Tensor(target.values).long() self.datanum = len(self.dataset) def __len__(self): return self.datanum def __getitem__(self, idx): out_dataset = self.dataset[idx] out_target = self.target[idx] return out_dataset, out_target # ネットワークの定義 class MyModel(nn.Module): def __init__(self): super(MyModel, self).__init__() self.fc = nn.Sequential( nn.Linear(input_num, 64), nn.ReLU(), nn.Dropout(0.5), nn.Linear(64, 32), nn.ReLU(), nn.Linear(32, 16), nn.ReLU(), nn.Linear(16, 8), nn.ReLU(), nn.Linear(8, 2) ) def forward(self, x): x = self.fc(x) return x
Pytorchで学習するためにデータセットクラスを定義します.
利用するために必要なPytorchで独自データセットを定義する方法についてはこちらを参照ください.
ネットワークは単純な5層のMLPを定義して,最終層で2つのパラメータを出力するようにしています.
- 学習
# ハイパーパラメータ初期化 criterion = nn.CrossEntropyLoss() model = MyModel().to(device) optimizer = optim.SGD(model.parameters(), lr=learning_rate, momentum=0.9) # データローダーの作成 train_dataset = MyDataset(X_train, y_train) test_dataset = MyDataset(X_test, y_test) train_loader = DataLoader(train_dataset, batch_size=BATCH_SIZE, shuffle=True) test_loader = DataLoader(test_dataset, batch_size=BATCH_SIZE, shuffle=False) # 学習 train_loss = [] for epoch in range(0, epochs+1): running_loss = 0.0 running_corrects = 0 model.train() for idx, (inputs, targets) in enumerate(train_loader): inputs, targets = inputs.to(device), targets.to(device) optimizer.zero_grad() outputs = model(inputs) _, preds = torch.max(outputs, 1) loss = criterion(outputs, targets) loss.backward() optimizer.step() running_loss += loss.item() * inputs.size(0) running_corrects += torch.sum(preds == targets.data) epoch_loss = running_loss / len(train_loader.dataset) epoch_acc = running_corrects.double() / len(train_loader.dataset) print('{}/{} Loss: {:.4f} Acc: {:.4f}'.format(epoch, epochs, epoch_loss, epoch_acc)) # テストデータによる評価データ取得 y_tests = [] y_preds = [] model.eval() with torch.no_grad(): for idx, (inputs, targets) in enumerate(test_loader): inputs, targets = inputs.to(device), targets.to(device) outputs = model(inputs) _, preds = torch.max(outputs, 1) outputs = F.softmax(outputs, dim=1) y_preds.append(outputs[:, 1].detach().cpu().numpy()) y_tests.append(targets.detach().cpu().numpy())
先ほど定義した MyDataset クラスを用いてPytorchでデータを呼び出すためのデータローダーを定義します.これを用いてモデルの学習とテストデータによる評価データの取得を実施します.
- 評価とモデル保存
# numpy arrayの結合 y_preds = np.concatenate(y_preds) y_tests = np.concatenate(y_tests) # ROC Curveの表示 fpr, tpr, thresholds = roc_curve(y_tests, y_preds) auc = auc(fpr, tpr) fig = plt.figure(figsize=(8, 6)) plt.plot(fpr, tpr, label='ROC curve (area = %.3f)' % auc) plt.xlabel('FPR: False positive rate') plt.ylabel('TPR: True positive rate') plt.title('ROC Curve') plt.legend() plt.grid() plt.show() # Confusion Matrixの表示 matrix_data = confusion_matrix(y_tests, np.round(y_preds), labels=[0, 1]) plt.figure(figsize = (10,7)) sns.heatmap(matrix_data, annot=True, cmap='Blues', fmt='4g') plt.show() # モデル保存 input_tensor = torch.rand(1, input_num) export_model = torch.jit.trace(model, input_tensor) export_model.save('../models/model.pth')
テストデータによって取得した評価データを用いてAUCと混合分布は以下の通りになりました.
AUCは91.3%とかなり高精度のモデルになっていることを確認できました.
また,混合分布からもTrue PositiveとFalse Negativeに大半は分類できていることが見て取れます.
モデル保存は torch.save を用いてモデル全体の情報を保持する形でデータ出力をしています.こちらに関しては別の記事にて詳細にまとめていこうと思います.


次からはここで作成したモデルをTorchServeを用いてデプロイしていきましょう.
デプロイ
本題のTorchServeにてモデルのデプロイをします.
大きな流れは以下の通りです.
- handlerの記述
- 作成した学習済みモデルのアーカイブ
- TorchServeでのデプロイ
まず始めにhandlerと呼ばれる推論ロジックを定義するための custom_handler.py ファイルを作成します.このファイルではモデルの読み込みやリクエストで受け取ったデータの前処理等を記述することができます.TorchServeではこのhandlerがエントリポイントになるため実行時にここで記述された内容が実行されます.デフォルトでいくつかのhandlerが用意されていますが,独自で作成したモデルには適応できないためカスタムhandlerを利用します.
今回作成したファイルは以下の通りです.
カスタムhandlerではBaseHandlerクラスを継承して独自の処理内容を記述したファイルを作成します.この際に initializeとhandle メソッドは必ず定義する必要があるので注意してください. 以下ではpreprocess メソッドでは前処理を postprocess 後処理の内容をオーバーライドして記述しています.
import os import torch import torch.nn as nn import torch.nn.functional as F from ts.torch_handler.base_handler import BaseHandler class ModelHandler(BaseHandler): def __init__(self): self.manifest = None self._context = None self.initialized = False self.model = None self.device = None def initialize(self, context): self.manifest = context.manifest properties = context.system_properties model_dir = properties.get("model_dir") self.device = torch.device("cuda:" + str(properties.get("gpu_id")) if torch.cuda.is_available() else "cpu") # Read model serialize/pt file serialized_file = self.manifest['model']['serializedFile'] model_pt_path = os.path.join(model_dir, serialized_file) if not os.path.isfile(model_pt_path): raise RuntimeError("Missing the model.pt file") self.model = torch.load(model_pt_path) self.initialized = True def preprocess(self, data): preprocessed_data = data[0]['body']['data'] if preprocessed_data is None: preprocessed_data = data[0].get("data") return torch.FloatTensor([preprocessed_data]) def inference(self, model_input): # Do some inference call to engine here and return output model_output = self.model.forward(model_input) return model_output def postprocess(self, inference_output): probs = F.softmax(inference_output, dim=1) results = [ { "<=50K": prob[0], ">50K": prob[1] } for prob in probs.tolist() ] return results def handle(self, data, context): model_input = self.preprocess(data) model_output = self.inference(model_input) return self.postprocess(model_output)
続いて torch-model-archiver を利用してモデルをTorchServeで扱う .mar 形式に変換します.handler オプションで先ほど作成した custom_handler.py を指定してアーカイブします.アーカイブされた .mar ファイルは export-path で指定したディレクトリに<model-name>.mar のファイル名で出力されます.以下のコマンドではmodel_storeディレクトリ配下にsevremodel.marファイルが出力されているはずです.
オプションの細かい説明は公式ドキュメントをご覧ください.
$ mkdir model_store $ torch-model-archiver --model-name servemodel \ --version 1.0 \ --serialized-file models/model.pth \ --handler handlers/custom_handler.py \ --export-path model_store
最後に torchserve コマンドによってデプロイを実行します.
先ほどアーカイブした servemodel.mar を指定してください.
これでデプロイは完了です.
$ torchserve --start \ --ncs \ --model-store model_store \ --models servemodel.mar
動作確認はヘルスチェック用のエンドポイント /ping に対してリクエストを投げてレスポンス内容を確認してください.statusに Healthy が返って来れば正常に動作しています.
$ curl curl http://127.0.0.1:8080/ping { "status": "Healthy" }
推論リクエスト
さて,TorchServeによってデプロイしたモデルに対して推論を実施してみましょう.
TorchServeのデフォルトの設定では2つのAPIサービスが立ち上がり,ポート番号8080ではInference APIが,ポート番号8081ではManagement APIが利用できるようになります.Inference APIで推論を行うためのエンドポイントは /predictions/<model name>/<version>となるため,今回デプロイしたモデル名を指定して /predictions/servemodel/1.0/ に対してPOSTリクエストを投げて結果を確認してみます.
$ curl -X POST -H 'Content-Type: application/json' -d '{"data": [0.030671, -1.063611, 1.134739, 0.148453, -0.21666, -0.035429, 0, 0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 0, 0, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 0, 0, 0, 0, 1, 0, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 0, 0]}' http://127.0.0.1:8080/predictions/servemodel/1.0/ { "<=50K": 0.8627053499221802, ">50K": 0.13729462027549744 }
無事に推論が行えて正常にモデルがデプロイできていますね.
詳細な設定によるカスタマイズやバッチ推論等も行えるようなので自身の利用用途に合わせて柔軟に対応させることができると思います.是非皆様も活用してみてください.
まとめ
今回はPytorchで構築したモデルをサービングするためのTorchServeについてご紹介しました.開発が盛んなPytorchコミュニティですので今後の発展が楽しみですね.
また,まだPytorchに関してそんなに詳しくないという方については少し内容が難しかったかと思います.そう言った方には以下のような書籍で学習することをおすすめします.こちらは私も日々参考に利用している書籍で,様々なアルゴリズムの実装例ととフレームワークの詳細な説明があるため1冊で網羅的にPytorchに関する学習をすることが可能です.