SHAPでモデルを解釈してみた
はじめに
XAI(Explainable AI)という言葉を聞いたことはありますでしょうか.
日本語では「説明可能なAI」と呼ばれていて,構築した学習モデルが入力に対してどのように出力に起因したのかというモデルの解釈性を示す分野として注目を集めております.機械学習のモデルはブラックボックスとなりがちなため,なぜそのような結果になったのかという解釈は一般的には難しい側面があります.こう言った課題はアカデミックな領域ではあまり問題とならない場合もあるのですが,ビジネスの現場では機械学習のアルゴリズム導入の妨げとなる要因になります.というのもシステムを構築してサービスを提供する企業において,想定していない挙動をとることに対して信頼性や安全性と言った観点で難色を示す場合が往往にしてあるからです.
そのため,今回は機械学習の解釈性という非常に重要なトピックを題材に,モダンな機械学習アルゴリズムと親和性が高く扱いやすいSHAPについて構築したモデルにおける活用方法を含めて説明します.
SHAPとは
SHAPとはブラックボックスしがちな予測モデルの各変数の寄与率を求めるための手法で,各特徴量が予測モデルの結果に対して正負のどちらの方向に対してどれくらい寄与したかを把握することによって予測モデルの解釈を行えるようになります. SHAPの理論は主に協力ゲーム理論におけるShaply Valueが由来となっており,協力ゲーム理論におけるプレイヤーを特徴量に置き換えて特徴量毎の貢献度(Shapley Value)を求めています.shapley valueの計算式は以下のように定義されます.
この式のの部分が組み合わせ数の逆数となっており,後半部分の
]はある組み合わせにおけるプレイヤーiの貢献度合いを示していることより,全ての組み合わせにおける貢献度合いの平均を算出していることになります.
このようにして全ての組み合わせにおける貢献度を求めることでShapley Valueが計算されることがわかります.
ただし,全ての場合でshapely valueを計算することができれば良いのですが,現実的な問題として特徴量が増えていった際に,特徴量同士の組み合わせ数が膨大になり有限な時間で計算が終わらないといった事象が発生します.そのため,実際には近似値を計算するなどの工夫が行われています.
より詳細な中身のロジックについては本家の論文を参照してみてください.
ライブラリについて
ここまで述べてきたSHAPの理論についてですが,この理論を実装したSHAPと言うライブラリがあります.
このライブラリでは最適化された計算手法やモデル解釈のための可視化メソッドが用意されており,我々が生成したモデルに対して簡単にSHAP Valueを計算することをサポートしてくれます.モデルにおける各特徴量の貢献度を計算する仕組みが内部実装されている関係で,サポートされていないアルゴリズムやライブラリでのモデルは扱うことができませんが,有名なアルゴリズムは既にサポートしているので特殊な場合を除きすぐに実装して計算することができます.
SHAPライブラリで解釈を行うことが可能な対応しているアルゴリズム(ライブラリ)について紹介します.
まず,木系のアルゴリズムでは以下のモデルがSHAPで扱うことができます.
- XGBoost
- LightGBM
- CatBoost
- scikit-learn tree model
- pyspark tree model
SHAPライブラリでは上記の木系アルゴリズムを高速に処理するためにC++ライブラリとして実装されています. その他にもニューラルネットワークのフレームワークではTensorflowとKerasをサポートしており,一部の機能ではPytorchも利用できるようになっています.
実際にSHAPライブラリの具体的な利用方法を知りたい場合は本家のGithubを参照することをお勧めします.というのも実装例として多くのJupyter NotebookによるサンプルをREADMEに用意していることから参照することで実装と出力イメージが両方掴めるため,これからSHAPで初めて解釈を実施してみようと言う方は一読してみてください.
インストール
SHAPライブラリのインストール方法を実行環境の情報と併せて以下に記載します.
ProductName: Mac OS X ProductVersion: 10.14.6 Python: 3.6.9
今回はLightGBMとXgboostのモデルに対してSHAPによる解釈を実施していくため,まず下準備としてLIghtGBMとXgboostのライブラリをインストールします.
$ pip install lightgbm==2.3.1 xgboost==1.0.0
続いて,本命のSHAPをインストールです.
$ pip install shap==0.35.0
インストール自体はpipで非常に簡単にインストールすることができるので導入しやすいと思います.
データセット
扱うデータセットはUCI machine learning repositoryで公開されているデータセット一覧の中から「Wine Quality Data Set」を利用します.このデータセットはワインの品質に関する情報を含んでおり,白ワインと赤ワイン別にサンプルデータが分割されているためフラグを自身で付与することで2値分類用のデータセットを作成することができます.
https://archive.ics.uci.edu/ml/datasets/Wine+Quality
本記事ではこのデータセットを用いて品質に関する情報から白ワインと赤ワインの2値分類の問題としてモデルを作成し,SHAPによるモデルの解釈を行います.
具体的なカラムを参考情報として以下にまとめておきます.
| カラム名 | データ型 | 説明 |
|---|---|---|
| sulfur dioxide | float64 | 二酸化硫黄 |
| chlorides | float64 | 塩化化合物 |
| density | float64 | 濃度 |
| sulphates | float64 | 亜硫酸塩 |
| volatile acidity | float64 | 揮発酸(酢酸) |
| pH | float64 | 水素イオン指数 |
| residual sugar | float64 | 残糖量 |
| alcohol | float64 | アルコール |
| fixed acidity | float64 | 酒石酸濃度 |
| free sulfur dioxide | float64 | 遊離亜硫酸濃度 |
| citric acid | float64 | クエン酸濃度 |
| quality | int64 | ワインの味 |
モデル作成
続いてモデル作成を実際のコードと併せて説明していきます.
今回はLightGBMとXgboostの2つのそれぞれでモデルを作成します.
この2つのモデルを選択した深い意味は特にはないのですが,私がベースラインのモデルを作成する際に頻繁に利用するアルゴリズムということで2つのモデルを利用しました.
まずは各種必要なライブラリのインポートです.
基本的な分析関連のライブラリをインポートしておきます.
可視化ライブラリはmatplotlib,データ操作に関してはpandas,numpy,scikit-learnを利用します.
import numpy as np import pandas as pd import xgboost as xgb import lightgbm as lgb import seaborn as sns import matplotlib.pyplot as plt from sklearn.model_selection import train_test_split from sklearn.metrics import roc_auc_score, roc_curve, auc from sklearn.metrics import classification_report
先ほど解説したUCIのワインに関するデータをpandasを利用してDataFrame形式で読み込みます.白ワインと赤ワインを識別するカラムはデフォルトのcsvファイルには含まれていないため,自分で作成する必要があります.そのため,今回は新たに class というカラムを用意して赤ワインと白ワインを識別するフラグを用意しています.
# データの読み込み wine_red = pd.read_csv("../data/winequality-red.csv", sep=";") wine_white = pd.read_csv("../data/winequality-white.csv", sep=";") # classカラムを追加( 赤ワインが 0, 白ワインが 1 ) wine_red["class"] = 0 wine_white["class"] = 1 # 2つのデータセットを結合 wine = pd.concat([wine_red, wine_white], axis=0)
作成したデータを学習データセットとテストデータに分割します.
全体の2割をテストデータとして利用します.
# 固定パラメータの指定 SEED = 42 TEST_SIZE = 0.2 target = "class" predictors = [i for i in wine.columns if i not in target] # データの分割 X_train, X_test, y_train, y_test = train_test_split( wine[predictors], wine[target], test_size=TEST_SIZE, random_state=SEED )
LightGBM
ここからはLightGBMでのモデル学習と精度確認をしていきます.
ハイパーパラメータは2値分類で学習するための値を指定して学習します.
イテレーションの回数は5000回として,early stoppingとして100を設定してモデルを学習します.
# Lightgのハイパーパラメータ lgb_params = { 'task': 'train', 'max_depth': 10, 'metric': 'auc', 'objective': 'binary', 'boosting': 'gbdt', 'learning_rate': 0.005, 'seed': SEED, 'num_threads': 8, 'early_stopping_round': 100, 'subsample': .8, 'min_gain_to_split': .1, 'lambda_l1': 1, 'lambda_l2': 0, 'min_child_weight': .8, 'feature_fraction': .8, 'num_leaves': 31 } # モデルの学習 lgb_train = lgb.Dataset(X_train, y_train) lgb_eval = lgb.Dataset(X_test, y_test) lgb_model = lgb.train( params=lgb_params, train_set=lgb_train, num_boost_round=5000, valid_sets=lgb_eval ) # テストデータによる推論 y_pred = lgb_model.predict(X_test, num_iteration=lgb_model.best_iteration) # 評価指標の計算 fpr, tpr, thresholds = roc_curve(y_test, y_pred) roc_auc = auc(fpr, tpr) # 重要変数とROC-Curveの可視化 fig, axes = plt.subplots(nrows=1, ncols=2, figsize=(13,6)) feat_imp = pd.Series(lgb_model.feature_importance(), index=X_test.columns).sort_values(ascending=False) feat_imp = feat_imp.head(30) feat_imp = feat_imp.sort_values(ascending=True) feat_imp.plot(kind='barh', title='Feature Importance', ax=axes[0], color=sns.color_palette()[0]) axes[0].set_xlabel('Feature Importance Score') axes[1].plot(fpr, tpr, label='ROC curve (area = %0.3f)' % roc_auc) axes[1].plot([0,1], [0,1], 'k--') plt.xlabel('False Positive Rate') plt.ylabel('True Positive Rate') plt.title('ROC Curve') legend = axes[1].legend(frameon=True, loc='lower right', fontsize = 'medium') # 凡例 frame = legend.get_frame() frame.set_facecolor('white') frame.set_edgecolor('gray')
学習したモデルの重要変数とROCを可視化したグラフは以下に示す通りになりました.ROC-AUCは99.7%と高精度なモデルを学習できているようです.
続いて,重要変数を見てみると最も予測結果に寄与している変数はtotal sulfur dioxideということでワインの酸化防止剤として活用されて二酸化硫黄の含有率がワインの識別に最も関係があることが結果として見て取れます.逆に quality はワインの識別には関係ないことがわかりますね.

Xgboost
続いてXgboostによるモデル作成と精度確認の部分になります.
ハイパーパラメータなどはLightGBMとほぼ同様になるように設定しています.
# xgboostのハイパーパラメータ xgb_params = { "booster": "gbtree", "max_depth": 10, "objective": "binary:logistic", 'eval_metric': 'auc', "eta": 0.005, "seed": SEED, "nthread": 8, "subsample": 0.8, "gamma": 0, "alpha": .1, "lambda": 0, "min_child_weight": .8, "colsample_bytree": .8, "max_leaves": 31 } # モデルの学習 xgb_train = xgb.DMatrix(X_train, y_train) xgb_test = xgb.DMatrix(X_test, y_test) evals_result = {} xgb_model = xgb.train( xgb_params, xgb_train, num_boost_round=5000, early_stopping_rounds=500, evals = [(xgb_test, 'eval'), (xgb_train, 'train')], evals_result=evals_result ) # テストデータによる推論 y_pred_xgb = xgb_model.predict(xgb_test) # 評価指標の計算 fpr, tpr, thresholds = roc_curve(y_test, y_pred_xgb) roc_auc = auc(fpr, tpr) # 重要変数とROC-Curveの可視化 fig, axes = plt.subplots(nrows=1, ncols=2, figsize=(13,6)) feat_imp = pd.Series(xgb_model.get_fscore()).sort_values(ascending=False) feat_imp = feat_imp.head(30) feat_imp = feat_imp.sort_values(ascending=True) feat_imp.plot(kind='barh', title='Feature Importance', ax=axes[0], color=sns.color_palette()[0]) axes[0].set_xlabel('Feature Importance Score') axes[1].plot(fpr, tpr, label='ROC curve (area = %0.3f)' % roc_auc) axes[1].plot([0,1], [0,1], 'k--') plt.xlabel('False Positive Rate') plt.ylabel('True Positive Rate') plt.title('ROC Curve') legend = axes[1].legend(frameon=True, loc='lower right', fontsize = 'medium') # 凡例 frame = legend.get_frame() frame.set_facecolor('white') frame.set_edgecolor('gray')
当然ですが,こちらもLightGBMの結果と同様にほとんど同じ結果になっています.精度は誤差の範囲ですが99.9%とLightGBMより高い精度のモデルになりました.

SHAP Value
ここからが本題のSHAPになります.
それぞれのモデルでSHAP Valueの計算と可視化をしてみます.
TreeExplainerクラスにてモデルを入力してインスタンスを生成し,shap_valuesメソッドを実行するだけで簡単にSHAP Valueを計算することができます.
SHAPライブラリ内ではLightGBMのpredictメソッドを実行しており,その際にパラメータの pred_contrib を指定してSHAP Valueを求めています.また,Xgboostも同様の方法でSHAP Valueを計算しています.
# LightGBMのSHAP Valueの計算 lgb_explainer = shap.TreeExplainer(lgb_model, X_train) lgb_shap_values = lgb_explainer.shap_values(X_train) # XgboostのSHAP Valueの計算 xgb_explainer = shap.TreeExplainer(xgb_model) xgb_shap_values = xgb_explainer.shap_values(X_train)
SHAP Valueを計算した後は可視化をします.
可視化にはいくつかの種類がありますので自身で適切な可視化を選択する必要があります.試しにViolinPlotとDependencePlotで結果を見てみます.SHAPライブラリでは複数の可視化パターンを用意しているためGithubを参考にして実施したい解釈に合わせて適切な可視化パターンを選択してみてください.
Violin Plot
# LightGBMでのViolin Plotの可視化 shap.summary_plot(lgb_shap_values, X_train) # XgboostでのViolin Plotの可視化 shap.summary_plot(xgb_shap_values, X_train)


Violinプロットを見てみるとパラメータの値が結果に対してどのように寄与しているのかを把握することができます.最上位にきている total sulfer dioxide を見てみると,この値が大きいほど予測結果を白ワインである確度が高くなるように作用していることがわかります.一方で chlorides を見てみると逆に作用しており,値が大きいほど赤ワインである方向に作用しているようです.このように属性情報の値の大きさがどちらに作用しているのかを確認することでモデルの入力と出力の関係を理解することに繋げられます.
Dependence Plot
# LightGBMでのPartial Dependence Plotの可視化 shap.dependence_plot("rank(0)", lgb_shap_values, X_train) # XgboostでのPartial Dependence Plotの可視化 shap.dependence_plot("rank(0)", xgb_shap_values, X_train)


Dependence Plotを見てみると,単一の特徴量に対して全てのパラメータがどのように予測結果に影響しているのかを理解することができます.また,別のパラメータとの交互作用も合わせて確認することができます.交互作用を確認したいパラメータを指定する場合は interaction_index を引数で指定してあげれば簡単に可視化できます.
今回の結果では total sulfer dioxide の値が大きくなるとSHAP Valueが大きくなっていることが見て取れます.LightGBMもXgboostでも同様の結果になっていますね.このように単一の特徴量における予測結果への影響が線型的に単調増加している場合は解釈が容易なのですが,必ずしもそういう結果になるとは限りません.次の項目では解釈をしやすくするためのMonotonic Constraints(単調制約性)について簡単に記載しておきます.
Monotonic Constraints
Monotonic Constraintsとは単調制約性のことを指します. つまり,一般的に特徴量が与えるモデルへの影響は複雑な作用をする場合が往々にしてありますが,特徴量がモデルへの与える影響を単調増加(減少)になるように制約を与えるということになります.
今回の例では単調制約性を与えてないない場合は citric acid は以下のように0.4まではSHAP Value値が大きくなりますが,0.4以降ではSHAP Valueが小さくなっていきます.このような場合にMonotonic Constraintsを与えた場合にどのような効果が得られるのかを確認して見ましょう.

Monotonic Constraintsを設定する方法は簡単で学習時のパラメータに制約項目を指定するだけです.事前に特徴量が目的変数に対してどのような相関があるのかを調べておき,負の相関,無相関,正の相関のそれぞれに応じて -1, 0, 1 を指定します.今回は正の相関を指定するため1を指定します.
# Xgboostのハイパーパラメータ xgb_params = { "booster": "gbtree", "max_depth": 10, "objective": "binary:logistic", 'eval_metric': 'auc', "eta": 0.005, "seed": SEED, "nthread": 8, "subsample": 0.8, "gamma": 0, "alpha": .1, "lambda": 0, "min_child_weight": .8, "colsample_bytree": .8, "max_leaves": 31, "monotone_constraints": "(0, 0, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0 )" # 単調制約性 } # モデルの学習 xgb_model_mono = xgb.train( xgb_params, xgb_train, num_boost_round=5000, early_stopping_rounds=500, evals = [(xgb_test, 'eval'), (xgb_train, 'train')], evals_result=evals_result ) # SHAP Valueの可視化 xgb_mono_explainer = shap.TreeExplainer(xgb_model_mono) xgb_mono_shap_values = xgb_mono_explainer.shap_values(X_train) shap.dependence_plot("rank(9)", xgb_mono_shap_values, X_train)
先ほどの図と比べても変化は一目瞭然ですね.
パラメータで指定した正の相関のように値の増加に伴ってSHAP Valueが単調増加していることが分かります.このように解釈をしやすいようにモデルに制約を与えることもできます.この制約を与えてモデルを作成した場合には予測精度が低下する場合もあるため,モデル精度を下げたくない場合は注意してください.

まとめ
今回はSHAPの簡単な理論と木系のアルゴリズムにてSHAPの扱い方をモデルの作成からSHAP Valueの可視化までを通じて説明しました.XAIはデータ分析においても非常に重要なトピックでありますし,ビジネスサイドでも役に立つということで是非活用してみてください.
SHAPライブラリはDeepLearningのフレームワークでも扱うことができるため,今後はそちらも試して見たいと思います.
リモートワーク効率化に向けて自宅環境の整備をしてみた
今回の記事は本ブログの趣旨から外れるため投稿するか迷いましたが,是非皆さんも自宅整備を実施してもらいたいと思ったため例外的な記事として投稿します.まだ,自宅環境を整備していない方はこの機会に是非整備してみてください.
自宅環境は整備しよう
結論から述べるとテレワークにおける自宅環境は絶対に整備するべきだと思います.
世界中に大きな影響を及ぼしてるCOVID-19により,私たちの生活は今現在大きな変革を求められています.例えば,集団感染を未然に防ぐために学校ではリモート授業などの導入によって教育の仕方が変わり,企業では時差出勤やリモートワークなど働き方に変化が起きています.日本企業では皮肉にもこのパンデミックによって,大きくIT化が推進されたと言うのも事実だと思います. また,日本という国のIT化における課題も垣間見れましたね.特別給付金のオンライン申請が実は手動だったという真実には驚きを隠せませんでした.これは,システムを実際に使っている人に問題があるのではなく,システム導入を主導していた側の目的に問題があると個人的には思うので,今回の結果を踏まえて改善していってくれることを期待します.
さて,新しい生活様式としてリモートワークが主軸になりつつ過程で,改めてオフラインでの業務が重要だと感じた人や在宅だと誘惑が多くて集中できないなど様々な価値観を皆さんも抱いていると思います.
ですが,私がここで私が言いたいことはオフィスと自宅の環境が異なる状況下でリモートワークで生産性が落ちたという安直な解に落とし込まないでということです.普段慣れ親しんだ作業環境と異なる環境で作業すれば,生産性が落ちるのは必然です.オフィスでの作業を想定してここでは記載しますが,少なくともデスク,パソコン,ディスプレイ,マウス,キーボードの最低限この5つだけでもオフィスと同じ水準の環境を揃えることが重要だと思います.
本記事ではリモートワークのメリットが多いということに気づいたにも関わらず,COVID-19が収束したら全てをオフラインに戻すと言った安直な考え方をしないで,少しづつでもオンライン化が進んで新しい技術やツールが生み出される世の中になってくれることを期待して私が整備した自宅環境と環境整備による効果をまとめました.
購入した機器
早速,私が実際に購入した備品と機器について記載していきます.
私がリモートワークを実施する中で揃えた物は以下の5つです.
- デスク
- ディスプレイ
- マウス
- キーボード
- PCスタンド
あまりコストは掛けたくないとは思っていたので必要最低限の物だけにしました.また,デスクに関しては家の間取りとの兼ね合いで選んでおりますが,その他の物はオフィスで利用していた物に寄せて選んでおります. どうしてもコストを掛けたくないという方はディスプレイとマウスとキーボードを揃えればQoLが格段に上がりますので騙されたと思って整備してみましょう.
次からは具体的に購入した詳細を記載していきます.
デスク
私が購入したデスクはニトリのシステムデスク(ザッキー 110 WW)です.
サイズは幅110cm×奥行53cm×高さ115cmでありデスクスペースと本棚スペースを同時に確保できる点が購入の決め手になっています.
やはり業務上たくさんのメモをとったり書籍を閲覧することからデスク1つで収納も兼ねているのはポイントが高いです.デスクの下にも物が置けるスペースがあるのでデスクを常にスッキリした状態に保てるので綺麗好きな人にもおすすめです.
ディスプレイ
ディスプレイの選択は非常に悩みましたがコスパを考慮してLG モニター ディスプレイ 29WL500-B 29インチにしました.
業務では上位機器にあたる「LG モニター ディスプレイ 34WL850-W 34インチ」を利用しており,同じ物にしたかったのですが34インチのディスプレイをデスクにおいた際の圧迫感を気にしてインチが小さいディスプレイにしました.
結果としては29インチにしてして良かったです.ディスプレイのサイズは幅69.8cm×奥行20.9cm×高さ41.1cmとなるため幅には若干の余裕があるのですが,実際に置いてみると29インチでも多少の圧迫感があるので34インチだったらと想像すると恐ろしいです.
/HDR/IPS 非光沢/FreeSync対応/HDMI×2")
- 発売日: 2019/09/26
- メディア: Personal Computers
マウスとキーボード
続いてマウスとキーボードです. マウスは端末がMacbookProということもあり,MagicTrackPad2を利用しています.キーボードはHappy Hacking Keyboard Lite2(英語配列)ですね.
この2つに関しては基本的には会社で利用しているものと同じ物にしています.
HHKBに関してはProfessionalの方が絶対に良いとの声が聞こえてきそうですが,個人的には打鍵した際の感覚と少し音がうるいさい方が好きなのでLiteを利用しています.

- 発売日: 2015/10/14
- メディア: Personal Computers
PCスタンド
最後にPCスタンドですが,こちらは LAMPOクラムシェル ノートパソコンスタンド マックブック PCスタンド にしました.
業務では利用していないのですが,購入したデスクがそこまで広くはないことからディスプレイとMacbookProを置いてしまうとほとんどスペースがなくってしまうためMacbookProを据え置きの端末として利用するためにスタンドを購入・利用しています.
ディスプレイがワイドモニターであるためMacBookProの画面がなくても2画面での作業と同等の環境が再現できるのでMacのディスプレイは使わなくても問題ないですね.
")
自宅整備を実施して良かったこと
ここまでで購入した備品・機器について話してきましたが,ここからはそれらを導入して良かったことについて記載していきます.
生産性
やはり環境を整備する前と後では作業効率が格段に上がりました.
特にディスプレイを導入してからは作業スピードが2倍ほど向上したように思います.
調べ物をしながら作業を行うという方は絶対にディスプレイを導入して2画面の環境を用意することをオススメします.複数のアプリケーションを移動する度に目がちらついて作業に集中できないなんてこととはさよならしましょう.
モチベーション維持
これは全員に当てはまるとは言い切れませんが,私はリモートワークにおけるモチベーション維持に繋がりました.
家では誰かに常に監視されている訳ではないため集中して業務を遂行し続けるには個人の強い意思が必要になってきます.少しでもその意思を手助けするためにデスク環境が綺麗で作業しやすいことが起因すると感じます.
また,デスクに座ることで作業を開始するぞという気持ちが切り替えられるようになったので,リモートワークが始まるまでに気持ちが切り替えられないと言った人にもデスクが整備されているとオフィスに来て作業しているかのように気持ちの切り替えがスムーズに行える副次的な効果もあると思います.
個人ワーク時間が増加
良かったことの3つ目はリモートワークの環境を整備することで個人ワークの時間が増加したことです.
昨今ではプライベートの時間でスキルアップを図っている方が多いと思いますが,私もその内の一人で隙間時間や休日等を使って勉強したりしています.リモートワークの環境を整備したことによって机に向かう習慣を強制されたのか,意識することなく机に向かい個人ワークの時間が捗るようになりました.知識や技術は常に進歩しており,すぐに陳腐化するのでキャッチアップする時間を多く設けられるようになったことは個人的には思わぬ収穫でした.
まとめ
リモートワークの効率化に向けた自宅環境について,オフィスと同じ機器を整備するという観点で作業効率が向上するということを述べてきました.思わぬ収穫が誰しもあるはずなので,是非皆さんもリモートワークにメガティブな印象を持つのではなくどうすればリモートワークで生産性を高められるかを考えて行動してみてください.
今回はデータサイエンスやソフトウェアエンジニアリング以外の内容について記事を書きましたが,次はデータサイエンス関連の記事を書きたいと思います.
Pythonデータ分析100本ノックを実践【後半】
はじめに
本記事は過去記事のPythonデータ分析100本ノックを実践【前半】の続きの内容になっています.Pythonデータ分析100本ノックの書籍内容については前半にて言及しておりますので,Pythonデータ分析100本ノックとは?という方はまずはそちらを読んでみて下さい.
では早速,後半の50本ノックの内容を中心に書籍を実践してみた感想について記載していこうと思います.

後半部分の内容について
Pythonデータ分析100本ノックの後半では主に以下の3つのトピックを扱います.
大まかに後半の内容をまとめると最適化問題と分析結果のシミュレーションが中心の内容となっていて,画像処理や自然言語処理はおまけといった内容です.
少しだけ画像処理と自然言語処理の内容について言及しておくと,画像処理についてはOpenCVを用いた内容のみとなっておりHOG特徴量などといった人に対しての物体検出のみを扱っています.昨今の画像処理では当たり前となったCNNなどによる一般物体認識などの部分までは扱いません.
また,自然言語処理についても形態素解析が中心の内容となっております.この点については書籍内でも基本的な部分のみであることを明言しており,より広い知識を身に付けたいという方には専門書を読むことを推奨しています.
実践してみて
実践してみた所感を述べていきたいと思います.
まずは最適化問題と数値シミュレーションの部分についてです.
本書の中で私が一番取り組んでよかったと感じたのが最適化問題に関するノックの部分です.
というのもデータ分析を実施する中であまり最適化問題を扱う機会が多くはなく,学びが多いノックだったことが背景としてあります.データ分析や機械学習というとネットなどの情報ソースを見ても教師あり学習や教師なし学習,深層学習といった情報量が多く,あまり数理最適化問題を目にする機会がそもそも少ない気がしています(人によってはそんなことないと思いますが...).そのため,PuLP,CBCのインストールや数理モデル定式化の実装といった最適化問題を実践で扱うために技術を学習するツールとしては非常に良質のコンテンツだと思います.
また,最適化問題では解きたい問題の定式化がポイントだと思うのですが,数式が苦手な方でも問題なく知識を習得できるように本書は設計されているとも感じました.と言うのも,いきなり最適化問題による数式を定義するのではなく,アドホックに分析したプロセスを経て最終的に便利なツールとして数理最適化問題による解法を実践していく流れなので利便性を感じながら着実に知識を習得できるでしょう.
続いて,数値シミュレーションの項目です.
本書では最適化問題で得た解を検証する位置付けで数値上のシミュレーションを題材として取り扱っています.実現場におけるデータ分析においてもA/Bテストや予測モデルのオフライン検証など,モデリンングと併せて検証工程はデータ分析でも非常に重要なプロセスとなっています.数値シミュレーションにおけるノックの内容はその検証工程の重要性を訴える内容になっており,本書の中でも割と重要なポイントの1つかなと思います.
さらに,個人的な学びとしてはあるサービスの会員間のネットワークを可視化するといったお題に対して,複雑ネットワークの学問観点を用いて分析結果をアクションに繋げると言うアプローチが大きな学びとなりました.複雑ネットワークより扱うデータ傾向がスケールフリー型なのかスモールワールド型なのかといったインサイトを導出して次のアクション繋げると言うアプローチの方法は現場のデータ分析でも活用できるシーンが容易に想像できますね.
最後に画像処理と自然言語処理についてですが,ここは一言で述べてしまうと物足りないに尽きると思います.
やはり,昨今のトレンドを抑えた内容になっていない点は実際の現場で活きるデータ分析スキルからは程遠い内容だと感じました.
画像処理や自然言語処理の各領域で確立された技術は異なる領域の問題にも適応されることが頻繁に見受けられ,実際の現場でデータ分析に取り組んでいると様々なドメインの技術を複合的に扱って課題を解決しようとします.
この点では以下で示すような別の100ノックがありますのでそちらも併用して実践してスキルを身につけていくことが必要のようにも思います.
https://yoyoyo-yo.github.io/Gasyori100knock/yoyoyo-yo.github.io
http://www.cl.ecei.tohoku.ac.jp/nlp100/#ch1www.cl.ecei.tohoku.ac.jp
意外と苦労したポイント
ここでは本書の後半部分を取り組むに当たって少し苦労した点について記載しておきます.
1点目は最適化問題の実践における環境構築です.
以下に私が利用していた環境を記載します.
私自身はPuLPを使って最適化問題に関するノックを実践していましたが,振り返ってみるとノックの実践よりも環境構築に時間を取られてしまいました.
そこで,私は環境構築が容易でかつ高機能なソルバーが使えるGoogle社提供のOR-Toolsを利用することをおすすめします.本書で扱っているライブラリとは異なるため書籍に記載している解法とは若干異なってしまいますが,ライブラリで出来ること及び実現場を想定した技術スキルという観点ではOR-Toolsを用いた方が得策だと思います.是非これから100本ノックを初める方は最適化問題はOR-Toolsを用いて解いてみてください.
インストールもPipで簡単に行えますし,線形の最適化問題であれば以下のように直感的にコーディングすることができます.
- インストール
$ python -m pip install -U --user ortools
- 実装例
from __future__ import print_function from ortools.linear_solver import pywraplp # ソルバーの定義 solver = pywraplp.Solver('simple_lp', pywraplp.Solver.GLOP_LINEAR_PROGRAMMING) # 変数の定義 # xとyは0から無限の値を取りうる整数という定義 x = solver.IntVar(0.0, infinity, 'x') y = solver.IntVar(0.0, infinity, 'y') # 制約条件① # x + 2y <= 14. constraint0 = solver.Constraint(-solver.infinity(), 14) constraint0.SetCoefficient(x, 1) constraint0.SetCoefficient(y, 2) # 制約条件② # 3x - y >= 0. constraint1 = solver.Constraint(0, solver.infinity()) constraint1.SetCoefficient(x, 3) constraint1.SetCoefficient(y, -1) # 目的関数 # Objective function: 3x + 4y. objective = solver.Objective() objective.SetCoefficient(x, 3) objective.SetCoefficient(y, 4) objective.SetMaximization() # 最適化実行 solver.Solve() opt_solution = 3 * x.solution_value() + 4 * y.solution_value()
2点目はシミュレーションの項目における処理時間についてです.
本書の解法ではPythonでループを多用しているところが垣間見られ,4重のループにて解いている解法などがありました.実際のところ問題自体は解けるのですが,処理時間として30分ほど計算している処理などもありました.本の目的からすると処理時間は目的外のため考慮していないのかもしれませんが,実際のデータ分析の世界では処理時間は結構シビアに捉える必要があると感じています.本書で扱っているデータは大きくないため問題はそれほど大きくはないですが,数GBにもなるデータを扱うようになると処理スピードは非常に大きな問題へと発展します.
なので,もう少し本書でもその点について言及してくださる良かったと感じます.皆さんもPythonにおけるコーディングスキルや高速化の実装方法は平行して勉強していきましょう.
まとめ
今回はPythonデータ分析100本ノックにおける後半50本ノックの内容を中心に実践してみた感想について記載しました.100本という限られた条件の中で幅広いドメインを扱っており,体系的な知識獲得にはとても良いコンテンツだと思います.
対象者は以前に記載した前半部分の内容の通り,データ分析を実践し始めた方や知識を再確認したい人が適当だと思いますので,該当する方や興味がある方は是非100本ノックに取り組んでみてください.
MixConvの論文を読んでみた
MixConvとは
MixConv1とはConvolutional Nueral Networkのにおいてパラメータ数を減らしつつ,高精度を実現する新しい畳み込みを提案した手法のことです.本手法はGoogleBrainのMingxingTanとQuoc V. Leが発明したものになります. MixConvがどのように優れているのかというとdepthwise convolutionにおけるカーネルサイズの増加に伴う精度低下という課題を改善した部分にあります.以下ではMixConvの論文内容をまとめていこうと思います.
概要・イントロ
通常のConvNets(畳み込み)は画像分類やセグメンテーション,多くの応用で広く使われています.
最近のConvNetsにおけるトレンドは精度と効率の両方を改善することだそうです.このトレンドに従って,MobileNetやShuffleNet,NASNet,AmoebaNet,MnasNet,EfficientNetのようにdepthwise convolutionが取り入れられ現在のConvNetsにおいてますますより利用が増えていってると論文では記載されています.
通常の畳み込みと違って,depthwise convolutionのカーネルはそれぞれの個々のカーネルに適応され,これに従ってチャネル数の計算機的なコストを削減します.しかし,depthwise convolutionのカーネルを用いてConvNetsを設計することは重要と見なされる一方で,カーネルサイズの要素は見落とされがちです.通常の畳み込みの学習は3×3のカーネルが一般的に利用されますが,最近の研究結果では5×5や7×7のような大きいカーネルサイズが潜在的にモデルの精度と効率性を改善できることを示しています.
そこで,論文内では単純にカーネルサイズを大きくすると精度が向上するのかといった疑問について言及しており,MobileNetを題材に単純にカーネルサイズを大きくしていった場合の精度の遷移を確認しています.実際の結果は以下のようなグラフになっておりカーネルサイズが大きくなるとモデルサイズが大きくなり,より多くのパラメータが利用され,非常に大きなカーネルサイズは精度と効率の両方を損なう可能性があることを示しています.

論文では、モデルの精度と効率性を高めるには高解像度のパターンをキャプチャする大きなカーネルと低解像度のパターンをキャプチャする小さなカーネルの両方が必要だと述べた上で,さまざまな解像度でさまざまなパターンを簡単にキャプチャできるように、単一のたたみ込み演算でさまざまなカーネルサイズを混合する混合深さ方向たたみ込み(MixConv)を提案しています.下の図はMixConvの構造を表しており,複数のグループにチャネルを分割,異なるカーネルサイズをチャネルのそれぞれのグループに適応する仕組みを図示したものになります.

関連研究
関連研究ではEfficient ConvNetsとMulti-Scale Networks and Features,Nueral Architecture Searchの3つの観点で述べており,Efficient ConvNetとMulti-Scale Network and Featuresではそれぞれの観点でMixConvにおける差異を記載しています.そして,Nueral Architecture Searchの項目ではニューラルネットワークの設計プロセスを自動化してMixConvを用いた手動構築よりも優れたモデル(MixNet)を作成したとも述べています. 具体的な内容は割愛しますが気になる方は本家の論文を読んでみて下さい.既存研究との差異やMixNetをより詳細に理解できると思います.
MixConvの手法
MixConvの手法を簡単に述べるとチャネル(のグループ)ごとに異なる大きさのフィルターを使うようにしたDepthwise Convと言い換えられます.処理のイメージを簡略化したものを以下に示します.畳み込みの処理をg個のグループに分けて,グループごとに異なるカーネルサイズを適応して畳み込んだものをマージします.処理としては非常にシンプルでわかりやすいですよね.

また,論文内にはtensorflowを利用したmixconvの実装方法を紹介していますので,直ぐに自らの問題に適応することができます.pytorchではdepthwise_conv2dといったメソッドはないのでconv2dのパラメータにgroupのオプションがあるのでそれを利用することで再現できるようです.
def mixconv(x, filters, **args): G = len(filters) y = [] for xi, fi in zip(tf.split(x, G, axis=-1), filters): y.append(tf.nn.depthwise_conv2d(xi, fi, **args)) return tf.concat(y, axis=-1)
MixConvにおけるデザイン設計
論文では以下に示す大きく4つの観点別にパラメータやTipsに関する言及をしています.
- グループの数
- グループ毎のカーネルサイズ
- グループ毎のチャネル数
- Dilated Convolution
それぞの項目について内容を簡単に述べると,グループサイズについてはMobileNetを題材としてグループ数を4に設定することが一般的に安全としています.また,Neural Architecture Searchによってグループ数は1から5の間の範囲が安定して精度と効率性をより高める様子です.
次に各グループのカーネルサイズですが,基本的にグループには任意のカーネルサイズを設定しても良い一方で,各グループは異なるカーネルサイズを設定する必要があるとのことです.さらに,パラメータ数と計算量を減らす関係で3×3のカーネルサイズから初めて,グループ毎とに2i+1のカーネルサイズを設定するとのことです.つまり,4つのグループを想定した場合は{ 3×3, 5×5, 7×7, 9×9} といったカーネルサイズを設定するようです.
グループ毎のチャネル数は主に2つの設定方法があるそうです.1つは均一分割でそれぞれのグループは同じ数のフィルタを設定する方法で2つ目が指数分割でチャネル数の合計を の指数をかけて分割した値を設定するやり方です.具体例を用いて説明すると,32のチャネル数と4つのグループを想定した場合には均一分割では(8, 8, 8, 8)で指数分割では(16, 8, 4, 4)となります.
そして,最後のDilated Convolutionについては,より大きいカーネルサイズを扱うことによって増加するパラメータ数と計算量に対するTipsで,Dilated Convolutionを使用することで効率性を向上させることができると紹介しています.一方で精度については若干低くなるという懸念があると状況を鑑みて導入する必要がありそうです.
パフォーマンス
評価はMobileNetを題材に3×3のdepthwise convolutionをMixConvに置き換えた場合の分類タスクにおいて検証を実施しています.
ImageNetを用いた分類問題のパラメータ数と計算量,精度をまとめた表を以下に記載します.
| Network | MobileNet V1 (#Prams, #FLOPS, mAP) |
MobileNet V2 (#Prams, #FLOPS, mAP) |
|---|---|---|
| baseline 3×3 | 5.12M, 1.31B, 21.7 | 4.35M, 0.79B, 21.5 |
| depthwise 5×5 mixconv 35(ours) |
5.20M, 1.38B, 22.3 5.16M, 1.35B, 22.2 |
4.47M, 0.87B, 22.1 4.41M, 0.83B, 22.1 |
| depthwise 5×5 mixconv 357(ours) |
5.32M, 1.47B, 21.8 5.22M, 1.39B, 22.4 |
4.64M, 0.98B, 21.2 4.49M, 0.88B, 22.3 |
これをみてわかる通り,MixConvはより少ないパラメータ数とFLOPSであるにも関わらず,depthwise convolutionと同様もしくはそれ以上の精度を叩き出しています.
また,depthwise convolutionはより大きいカーネルサイズを用いることで精度低下という問題に直面するのに対して,MixConvはカーネルサイズの大きさによる精度低下の感度を鈍化させることが示唆されるため安定した精度を実現できるようです.
MixNet
さて,最後になりますが論文内ではnueral architecture serachを活用してMixConvに基づいたモデルとしてMixNetを提言しています.MixNetの詳細はここでは割愛しますが,以下のようなネットワークアーキテクチャを備えたモデルでMixConvの恩恵を簡単に受けることができます.ImageNetにおける評価ではSOTAで78.9%という高い数値を出しているため是非試しに使用してみて下さい.

まとめ
今回はMixConvについて論文の内容をまとめてみました.
MixConvの論文を読むことでConvNetにおける動向のキャッチアップを通じながら,MixConvの活用におけるポイントを理解することができました.論文を読むことは自身が取り組んでいる課題に対しての新しい解決策を得られる機会になることもしばしばあるので継続的に読むことをおすすめします.特に自らの専門領域とは直接的に関係ない内容であったとしても読むことで新しい発見があると感じます.
今後もまた別の論文を読んだ際には内容をまとめていこうと思います.
Pythonデータ分析100本ノックを実践【前半】
Pythonデータ分析100本ノックって?
Pythonデータ分析100本ノックとは秀和システムから出版されている書籍です.現場を想定したデータ分析に必要なスキルや処理方法を問題形式で習得することができる内容になっております.また,書籍内で扱うサンプルデータなどはWebからダウンロードすることができるので書籍を購入してすぐにデータ分析の問題を解くことが可能です.
今回は100本ノックの前半50本のノックを中心に書籍を実践してみた感想について記載していこうと思います.
書籍構成
書籍で扱う内容は大きく以下になっています.
ノック数の割合についてはデータ加工から機械学習の部分が大体半分を占めており,最適化問題が4分の1くらいで残りの4分の1で画像処理と自然言語処理といったボリューム感になっています.後半部分のそれぞれの項目をもっと深掘りして問題を解きながら理解したいという人には画像処理100本ノックや言語処理100本ノックといった有志で作成されているコンテンツがWeb上に公開されているのでそちらに取り組むのが良いと思います.
https://yoyoyo-yo.github.io/Gasyori100knock/yoyoyo-yo.github.io
http://www.cl.ecei.tohoku.ac.jp/nlp100/#ch1www.cl.ecei.tohoku.ac.jp
対象者はどれくらいの層なのか?
まずは前提となる必須スキルについて記載すると,Python操作に関する知識はマストで保有していないと厳しいと思います.
例えば,Pythonのインストール方法であったりとかPythonの基本文法などはデータ分析に関する書籍のため,書籍中では解説されておりません.いきなりライブラリをインポートする処理が最初から記載されているため,標準ライブラリ以外のデータ分析用のライブラリを利用したいことがない人が本書に取り組んだとしたらImportErrorで初めからつまづくと思います.
import numpy as np import pandas as pd
次にあると好ましいスキルとしてはデータ分析関連のライブラリに関する知識です.PandasやNumpyといったデータ分析において基本的なライブラリについては事前にどういうものかはある程度は把握しておいた方がベターだと言えます.
例えば,以下のようなcsvデータをDataFrameオブジェクトとして読み込むためのコードはデータ分析では一般的だと思いますが,ライブラリを扱ったことがない人はライブラリが何をしているのかを調べながら書籍を進めることになるためデータ分析スキルに注力することが難しいと思います.
import pandas as pd sample = pd.read_csv('test.csv', index_col=['number']) sample.head()
また,データ分析における基本的な理論(教師あり学習,教師なし学習,強化学習,分析評価指標等)が全くわかっていない人にとっても本書を進めるのはなかなか難しいのかなと思います.理由としてはデータ分析における理論的な話は一部記載されておりますが,十分な解説は記載されていないためソースコードを実践して動いたという感覚だけで満足してしまう可能性があるからです.
以上を踏まえて「Pythonデータ分析100本ノック」がどのように人に適しているのかをまとめると,やはりデータ分析の基礎を身に付けた人がこれから本格的に学習したいという人や日常的にデータ分析に取り組んでおり知識の再確認をする人向けの書籍だと感じます.
前半部分を実践してみて
それでは「Pythonデータ分析100本ノック」を実践してみた前半の50本のノックにおける個人的な感想を記載します.
まず,よかった点を述べるとデータ加工における前処理について自身が普段実装する方法よりも効率的に実装する方法を知れたことです.リアルな世界におけるデータ分析においては各種データは時系列データとなることが多いです.その点でデータフレームにおける日付の扱いなどを綺麗なソースコードで丁寧に解説・実践できる内容は素晴らしいと思いました.また,前処理を重点的に取り扱っている内容についても良かったこととして挙げられます.異なるスケールのデータフレームを加工してジョインし,学習用のデータセットを作成する内容については現場でデータ分析を実践しているかのような錯覚さえありました.
一方で,ここは微妙だなと思った点としては機械学習の評価の観点です.例えば製品需要を予測する回帰問題を想定した場合には機械学習によって得られた結果をMAEやMSE,MAPEといった評価指標で精度を確認していきます.しかし,この書籍では評価指標に関する具体的な言及はされないまま内容が進んでいくため,実際に現場で活用できる学習モデルを評価するためのスキルを身につけるためには別の学習が必要だと感じました.
ここまでで散々個人的な意見を述べてはきましたが,限られたページ数で分かりやすくデータ分析の実践方法を学ぶことができる書籍であることは間違い無いです.特に,データ分析における実践で役立つプロセスを体系的に学ぶことができる内容は素晴らしいと思いますので興味がある方は購入してみることをお勧めします.
まとめ
今回は「Pythonデータ分析100本ノック」を実践してきた中での前半部分における感想について記載しました.データ分析をこれから本格的に学習する人やデータ分析はある程度実践していて知識を再確認するといった人にとっては有益な書籍だと思うので皆様も是非読んでみてください.
後半の残り50本ノックについてはまた後日まとめていこうと思います.
DjangoのURLFieldでURLValidatorを設定できなかった話
やろうとしていたこと
事の経緯を簡単にお話すると,DjangoのRestFrameworkにて一部のモデルに対してURLFieldを用いてURL情報を保存するカラムを用意してAPIを作成していました.そんな矢先にURLに登録するデータにs3プロトコルを用いたURLを登録しようと思い,APIでPOSTリクエストを実行した時に問題は起きました.
問題との遭遇
URLFieldを設定した項目に対してS3プロトコルのURLを与えたデータをPOSTすると,なんとモデルの登録登録ができなかった...
{ "url": [ "Enter a valid URL." ] }
Djangoのドキュメントをよく見ると,以下のようにURLFieldではvalidatorとしてURLValidatorが設定されており,デフォルトではhttp,https,ftp,ftpsのみが有効なスキームとして検証されるそう.
URL/URI scheme list to validate against. If not provided, the default list is ['http', 'https', 'ftp', 'ftps']. As a reference, the IANA website provides a full list of valid URI schemes.
では,このURLValidatorの設定オプションでschemesにs3を指定して,URLFieldのvalidatorsにカスタムしたURLValidatorを設定してあげれば解決すると考えて実施してみたのですが,s3プロトコルは一向に許可されない不正なパラメータとして認識され続けていました.
from django.db import models from django.core.validators import URLValidator class Test(models.Model): s3_validator = URLValidator( schemes = ('http', 'https', 'ftp', 'ftps', 's3',) ) url = models.URLField(validators=[s3_validator])
原因
ドキュメントを読んでも理解できなかったのでDjangoのモデル部分を定義しているURLField Classのソースコードを確認してみました.
すると以下のような記述がありdefault_validatorsがクラス変数として認識されていることが発覚.そして,上位クラスであるFieldクラスにはこのdefault_validatorsを必ず読み込む処理が記述されており,validatorsによるバリデーション指定は追加のバリデーションを設定する仕様になっていることに気づきました.
class URLField(CharField): widget = URLInput default_error_messages = { 'invalid': _('Enter a valid URL.'), } default_validators = [validators.URLValidator()] def __init__(self, **kwargs): super().__init__(strip=True, **kwargs)
つまり,この場合はmodels.pyでURLFieldクラスのインスタンスを生成する際にvalidatorsにURLValidatorを指定したことによって2重で異なるバリデーションが設定されていたために期待する動作をしなかったということです.
解決策
具体的な解決策としては大きく2点あります.
1点目はURLFiledクラスをオーバーライドしてdefault_validatorを書き換える方法です.これによってdefault_validatorの内容が設定したバリデーションになるため期待通りの挙動をするようになります.
一方で,URLFieldを他のカラムでも利用している場合は設定したバリデーションが全てのカラムに適応されてしまうため注意が必要です.
from django.db import models from django.forms import UrlField as DefaultUrlField from django.core.validators import URLValidator class UrlField(DefaultUrlField): default_validators = [URLValidator(schemes=('http', 'https', 'ftp', 'ftps'. 's3'))] class Test(models.Model): url = models.URLField()
2点目はCharFieldにURLValidatorを設定してあげる方法です.
元々URLFieldはCharFieldを継承して定義しているため,CharFiledを用いてインスタンスを生成する際にURLValidatorを設定してあげれば挙動は同じになります.
こうすることで指定したインスタンスのみに個別のバリデーションを設定することができるため,1点目のクラスをオーバーライドする方法よりも影響範囲が限定的になります.
from django.db import models from django.core.validators import URLValidator class Test(models.Model): s3_validator = URLValidator( schemes = ('http', 'https', 'ftp', 'ftps', 's3',) ) url = models.CharField(validators=[s3_validator])
私の場合は2点目の方法を採用しました.
というのもフレームワークのクラスをオーバーライドして知らないところで影響が発生する可能性を排除したかったのと,複数のURLFieldで異なるバリデーションを利用する必要があったからです.
まとめ
今回の事象に遭遇して改めてドキュメントとソースコードをよく読むことだ大事であると認識しました.
昨今では新しいソフトウェアが目まぐるしい早さでGithub等で公開されております.ドキュメントも非常に見やすいことから内部的な処理についてあまり気にしなくても素晴らしい機能を扱うことができると思います.しかし,開発者としてはそれらを単純に利用するだけだとしても内部的な挙動はしっかり把握しておくことが重要ですね.
私も今回の学びを肝に命じて今後もソフトウェアと触れ合っていきたいと思います.
Django Rest FrameworkでAPIをサクッと作ってみた
Django Rest Framworkとは
Pythonのwebフレームワークと言えばDjangoがメジャーですよね.
Flask等の軽量フレームワークなどもありますが,世の中で一般的に必要とされる機能を実装しようとするとやはり機能不足を感じます.その点.Djangoは一通り必要な機能は備えており,迷ったらDjangoを利用すれば良いと思います.
そして,DjangoをベースとしてRESTfulなAPIを作成する場合に利用するのがDjango Rest Frameworkというライブラリです.今回はDjango Rest Frameworkを使ってAPIを作成してみましょう.
Django Rest Frameworkの仕組み
一般的なWebフレームワークと同様にMVCモデル(DjangoではModel-Template-Viewモデル)に従った考え方をベースとしてアーキテクチャは構成されております.そして,Django Rest FrameworkはTemplateの部分をSerializerに置き換えたものと考えておくと理解が早いと思います.
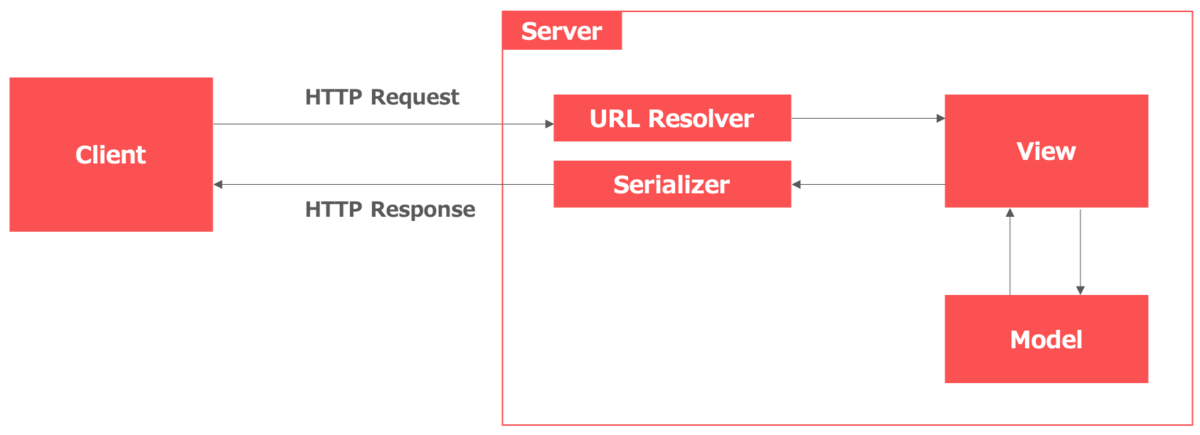
ClientがリクエストするとURL Resolverによってアクセスされた情報と一致するViewへルーティングを行いView内で定義した各種処理を行います.RESTfulであるということはURLとリソースが1対1で対応している設計思想に従うというになりますが,実装では必ずしもModelを経由して利用しなければいけない訳ではないので上記のアーキテクチャとは限りません.
インストール
では,早速インストールから環境の構築まで行なっていきましょう. 今回の環境は以下になります.
Python環境がインストールはされている前提でpipを使ってインストールします.
$ pip install django django-restframework
これだけでインストールは完了です.非常に簡単ですね.
プロジェクトの作成方法はDjango側が担っているのでDjangoで普段の要領でプロジェクトを開始する際のコマンドを実行していきます.
$ django-admin startproject rest_sample $ cd rest_sample/
次に今回のAPIとなるアプリを作成していきます.アプリ名は適当にpostとしていますが,ご自身の環境に合わせて適宜変更してください.
python manage.py startapp post
これまでのコマンドが正常に終了していれば以下のようなディレクトリ構成でファイルが生成されていると思います.
root/
├─ manage.py
├─ rest_sample
│ ├── __init__.py
│ ├── settings.py
│ ├── urls.py
│ └── wsgi.py
└─ post
├── __init__.py
├── admin.py
├── apps.py
├── migrations
├── models.py
├── tests.py
├── urls.py
└── views.py
これで準備は終わりですので本題の実装の方へ移っていきましょう.
実装方法
ここからが本題のDjango Rest Framework側の実装になります.
まずは rest_sample/settings.py でrest frameworkと作成したアプリの設定を行います.
INSTALLED_APPS = (
...
'rest_framework',
'post',
)
次にモデルの定義をpost/models.pyに適用します.
シンプルに投稿する内容のタイトルや内容を記録するカラムと作成日時等の付随する情報を定義しました.
class Post(models.Model): title = models.CharField(max_length=255) category = models.IntegerField() context = models.TextField(null=True, blank=True) created_at = models.DateTimeField(auto_now_add=True) updated_at = models.DateTimeField(auto_now=True)
そして,定義したモデルをデータベースに反映させるためにマイグレーションを実行します.デフォルトではsqlite3のデータベースに設定されているためそのまま利用します.
$ python manage.py makemigrations $ python manage.py migrate
続いて入力されたパラメータとシリアライズする処理を記述していきます.
Railsでいう所のハイパーパラメータと認識してもらうと理解が早いかと思います(実際には異なりますが).新しくpost/serializer.pyというファイルを作成してその内に処理を記述していきます.
from rest_framework import serializers class PostSerializer(serializers.ModelSerializer): class Meta: model = Post verbose_name = '投稿' verbose_name_plural = '投稿一覧' fields = ('id' 'title', 'category', 'context', 'created_at', 'updated_at')
viewにはコントローラーとなる処理を記述していきます.
viewにはいくつかのクラスがあるのですが,今回はModelViewSetクラスを用います.ModelViewSetクラスはGenericViewSetクラスを継承したクラスでmodelのCRUD操作がViewSetのアクションとして暗黙的に実装されるため,コードを簡易的に記述することができます.これだけでCURDの処理が記述できてしまうのには驚きですね.
from from rest_framework import viewsets from .models import Post from .serializer import PostSerializer class PostViewSet(viewsets.ModelViewSet): queryset = Post.objects.all() serializer_class = PostSerializer
最後にルーティングの記述をしていきます.
djangoのurlの設定とほとんど要領で設定できます.rest_sample/urls.pyに以下の内容を記述します.
from django.conf.urls import url, include from django.contrib import admin from post.urls import router urlpatterns = [ url(r'^admin/', admin.site.urls), url(r'^api/v1/', include(router.urls)), ]
import先のpost/urls.pyにDjango Rest Frameworkのルーターの設定を記述したら完了です.
from rest_framework import routers from .views import PostViewSet router = routers.DefaultRouter() router.register(r'posts', PostViewSet)
ここまで設定すればリクエストされたURLに応じてviewで定義したメソッドにルーティング処理が行われるようになりました.
これで作業は完了です.
APIサーバの実行
サーバの起動方法はDjangoの起動方法と同じです. ターミナル上で以下のコマンドを実行して見ましょう.
$ python manage.py runserver
サーバが起動できたら別のターミナルを開いてcurlコマンドでレスポンスを確認してみます. 初めはリソースがないためGETをリクエストしても何も面白くはないので,POSTメソッドでデータベースに新しいリソースを登録することを試みてみましょう.
$ curl -X POST -d "title=sample&category=4&context=message" http://localhost:8000/api/v1/post
{ "id": 1, "title": "sample", "category": 4, "context": "message", "created_at": "2020-3-15T21:23:12.54213Z", "updated_at": "2020-3-15T21:23:12.54213Z" }
ちゃんと動作していそうですね.
このようにDjango Rest Frameworkを用いることで簡単にAPIを作ることができます.APIを自作できるようになると他のサービスに作成した機能を組み込むことができるので開発効率の向上にも繋がりますね.
まとめ
今回は非常に簡単なCRUDの機能をDjango Rest Frameworkで実装する方法をご紹介いたしました.API機能を非常に簡単に実装できるため是非みなさんも使ってみてください.また,API認証の機能なども提供しており,サードパティ製のライブラリと組み合わせればOAuth認証なども実現できます. 今後は少し実際の利用に即した機能をご紹介して行ければと思います.